
Содержание
- Что такое режим ИИ в Google
- Как это работает
- Что такое Model Collapse и зачем Google помечает тексты нейросетей
- SynthID: как Google помечает контент
- Можно ли обойти SynthID
- C2PA и Content Credentials
- Что умеют детекторы AI-контента
- Позиция Google
- Позиция Яндекса
- Как оптимизировать контент под AI Mode
- Заключение
- FAQ
Google постепенно перестраивает поиск вокруг генеративного ИИ. Вместо привычной страницы с десятью ссылками пользователи все чаще получают готовый ответ, собранный нейросетью из нескольких источников. Один из главных элементов этой новой выдачи — режим ИИ, или AI Mode.
Что такое режим ИИ в Google
Это формат поиска Google, в котором пользователь получает не только список ссылок, а развернутый ответ, сгенерированный нейросетью. В основе лежат модели Gemini: они анализируют запрос, разбивают его на уточняющие подзадачи и собирают ответ из нескольких источников. Иначе этот формат называют AI Mode.
Если классический поиск показывает страницы, на которых может быть ответ, то режим ИИ Google пытается сразу сформулировать сам ответ. Рядом с ним Гугл может показывать ссылки на источники, дополнительные карточки, уточняющие вопросы, изображения, товары, локальные результаты и другие элементы.
Например, раньше по запросу «как выбрать CRM для малого бизнеса» пользователь видел список статей, рейтингов и рекламных объявлений. В AI Mode Google может сразу объяснить критерии выбора, сравнить типы CRM, задать уточняющий вопрос про бюджет или нишу и предложить несколько источников для дальнейшего изучения.
Чем он отличается от AI Overviews
AI Overviews и режим ИИ Google часто путают, однако это разные элементы поиска.
AI Overviews — это краткие ИИ-обзоры, которые появляются внутри обычной выдачи по некоторым запросам. Пользователь видит привычную страницу поиска, но над результатами или между ними может быть блок с ответом от ИИ.
Режим ИИ / AI Mode — это отдельный интерфейс поиска. В нем пользователь взаимодействует с Гуглом почти как с чат-ботом: задает вопрос, получает сгенерированный ответ, уточняет детали и переходит по источникам, если хочет изучить тему глубже.
AI Overviews дополняют классическую выдачу, а AI Mode Google частично заменяет ее. Поэтому даже сайт из топ-10 может получить меньше кликов, если пользователь закрыл свою задачу внутри ИИ-ответа.
При этом логика оптимизации у этих форматов похожа. Google так же выбирает страницы, которые прямо отвечают на вопрос, подтверждают факты, хорошо структурированы и вызывают доверие.
Сравнение AI Mode, AI Overviews и обычной выдачи
| Формат | Где появляется | Что видит пользователь | Значение для SEO |
|---|---|---|---|
| Обычная выдача | Страница результатов Google | Список ссылок, сниппеты, рекламные блоки, изображения, видео и другие элементы SERP | Важны позиции, CTR, сниппет, релевантность страницы и техническое состояние сайта |
| AI Overviews | Внутри обычной выдачи | Краткий ИИ-ответ со ссылками на источники | Часть кликов уходит в ИИ-ответ, но источники могут получить дополнительную видимость |
| Режим ИИ / AI Mode | Отдельный интерфейс Google | Развернутый ответ, уточнения, выбранные источники, карточки, рекомендации | Важны доверие к бренду, структура контента, экспертность, цитируемость и репутация источника |
Как работает AI Mode Google
Он работает не как обычная поисковая выдача. То есть Google не просто берет первые десять сайтов и пересказывает их. Система анализирует запрос, определяет намерение пользователя, подбирает несколько источников и собирает из них единый ответ.
Вот как выглядит процесс:
- Пользователь задает вопрос в разговорной форме.
- Google определяет интент: что человек хочет узнать, купить, сравнить или сделать.
- Система разбивает запрос на смысловые части.
- Google ищет источники, которые могут подтвердить каждую часть ответа.
- Gemini формирует краткое объяснение.
- В интерфейсе появляются ссылки на выбранные страницы, уточняющие вопросы и дополнительные элементы.
Поэтому обычное место в топ-10 не гарантирует попадание в режим ИИ Google. Поисковик может выбрать страницу, которая находится ниже в органической выдаче, но лучше отвечает на конкретный фрагмент запроса, содержит экспертные данные или чаще упоминается в авторитетных источниках.
Это особенно важно для информационных и коммерческих запросов со сложным интентом: «как выбрать», «что лучше», «почему падает трафик», «какой сервис подойдет для…», «как оптимизировать сайт под ИИ-поиск».
Как Google выбирает источники для ИИ-ответов
Гугл не раскрывает полный список факторов, по которым ИИ выбирает источники. Но по наблюдениям SEO-специалистов и логике работы генеративного поиска можно выделить несколько важных признаков. Чаще в ИИ-ответы попадает контент, который:
- прямо отвечает на вопрос пользователя;
- написан понятным языком и хорошо структурирован;
- содержит факты, цифры, исследования и ссылки на источники;
- имеет автора или эксперта, которому можно доверять;
- раскрывает тему глубже, чем поверхностные SEO-тексты;
- содержит определения, списки, таблицы, сравнения и короткие выводы;
- упоминается на других сайтах, в медиа, соцсетях, форумах и справочниках;
- связан с брендом, у которого есть репутация в теме.
Для генеративного поиска Google важно не только то, что написано на странице, но и то, как поисковик понимает сущность бренда, автора и сайта в целом. Если компания регулярно публикует экспертные материалы, получает упоминания в отрасли и подтверждает данные источниками, у нее больше шансов стать источником для AI Mode.
Что такое Model Collapse и зачем Google помечает тексты нейросетей
74% новых веб-страниц содержат материалы, созданные ИИ. К такому выводу пришли в Ahrefs: исследователи изучили 900 000 страниц, опубликованных в 2025 году. Полностью людьми написаны только 26% новых материалов.
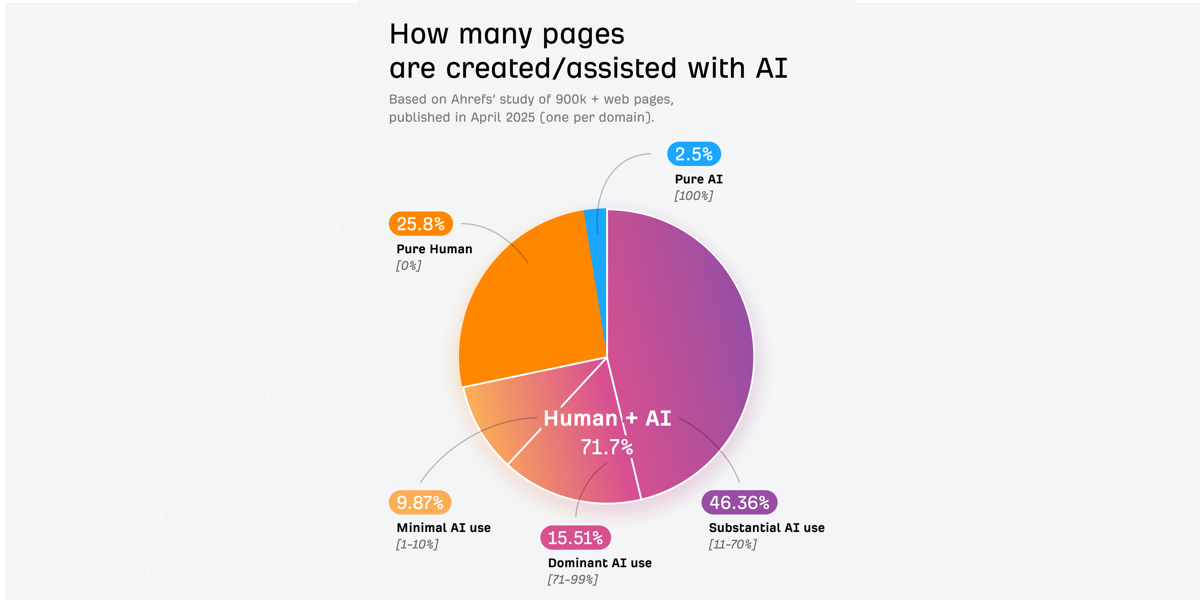
Цифра тревожная. Но есть и более серьезный сигнал: Google уже пометил метками SynthID более 10 миллиардов единиц контента. Поисковик не только следит за потоком текстов от нейросетей, он выстраивает систему, которая помогает их помечать, отслеживать и отсеивать.
Зачем? Из-за проблемы, о которой в SEO говорят нечасто: когда нейросети учатся на текстах, написанных другими нейросетями, качество их ответов начинает падать. Это называют коллапсом моделей.
Model collapse — это деградация языковой модели, когда ее учат на текстах, которые сгенерировали другие модели. Исследование в Nature показало, что если снова и снова кормить модель ее же машинными текстами, ее язык беднеет. Она пишет однообразнее, хуже и постепенно теряет важные особенности живой речи.
Вот самый наглядный пример из этого исследования: модель попросили написать текст о средневековой архитектуре. После четырех циклов обучения на текстах нейросетей она вместо этого выдала бессвязный текст о зайцах-русаках. Прошло всего четыре цикла, и модель уже не помнит, о чем ее спрашивали.
По оценке Epoch AI, открытые тексты, написанные людьми и пригодные для обучения моделей, могут иссякнуть уже в 2026–2032 годах.
Google помечает материалы нейросетей не для того, чтобы наказывать авторов, а чтобы отсеивать машинный текст при обучении новых моделей. Поисковику нужно отличать человеческие тексты от сгенерированных, иначе следующие версии его моделей станут хуже.
SynthID: как Google помечает контент
SynthID — технология Google DeepMind, которая встраивает в сгенерированный контент цифровую метку. Она работает во всех генеративных сервисах Google, но для текста, изображений, звука и видео немного иначе.

Текст: метка в выборе слов
Когда модель пишет текст, она каждый раз выбирает следующее слово из нескольких вариантов. SynthID слегка сдвигает их вероятности, чтобы оставить в тексте скрытую метку. Читатель этого не заметит: качество текста почти не меняется, а различия видны только в статистике.
Лучше всего система работает с длинными свободными ответами. С короткими и строго фактическими ей труднее, потому что выбор слов там слишком мал.
Изображения: метка в структуре картинки
В изображениях SynthID прячет знак в частотной структуре картинки. Глаз его не видит, но система может распознать метку даже после обрезки, сжатия и простой обработки.
Аудио и видео: метка в самом потоке
В аудио (Lyria) и видео (Veo) SynthID встраивает метку прямо в поток данных. NotebookLM тоже использует эту технологию и помечает подкасты, которые создает сам.
Ограничение SynthID
SynthID работает только в сервисах Google: Gemini, Imagen, Lyria и Veo. Если текст, картинку или видео создали в ChatGPT, Claude, Midjourney или Llama, SynthID их не распознает.
Почитать по теме: Как написать текст на сайт с помощью ChatGPT: советы и промпты
Можно ли обойти SynthID
Да, и это уже сделали. В декабре 2025 года Алексей, специалист по поисковому продвижению из Санкт-Петербурга, решил проверить, насколько надежно SynthID защищает изображения. Он сгенерировал 50 картинок в Imagen, перевел их в другой формат и вернул обратно. После этого детектор SynthID не распознал 35 изображений из 50. Качество почти не пострадало.
Но это еще детский сад по сравнению с тем, что показал проект reverse-SynthID на GitHub.
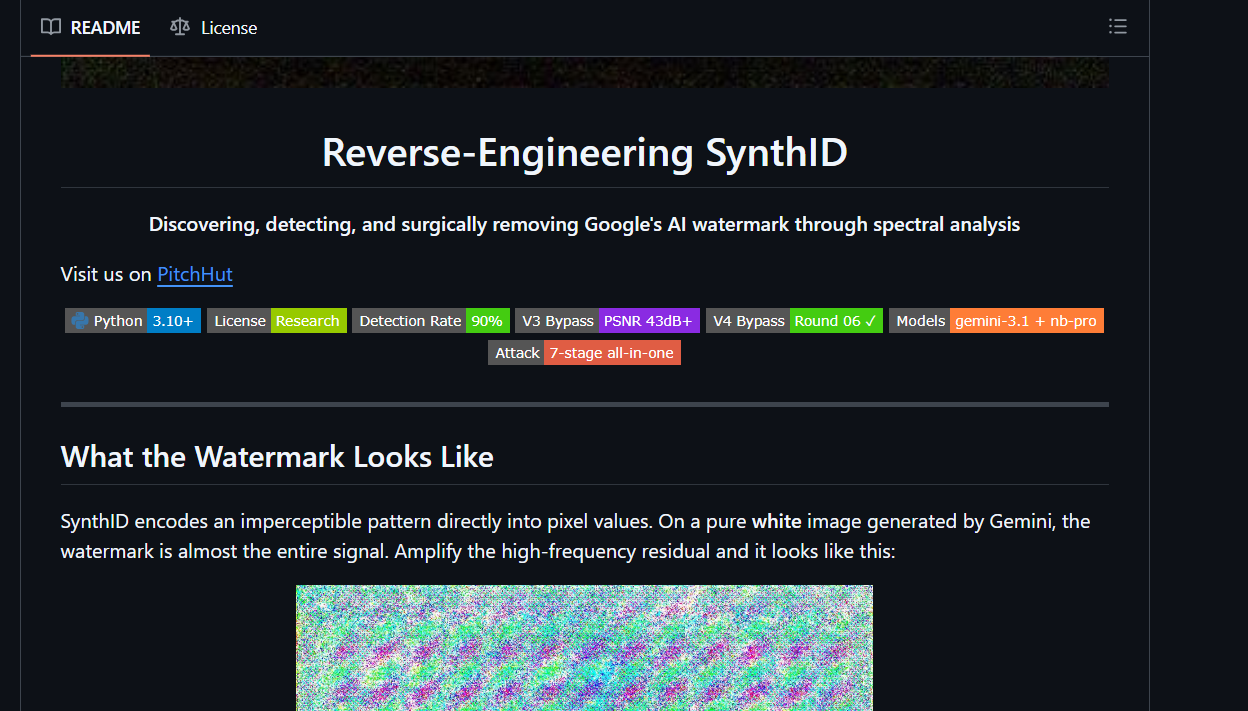
Трехэтапный взлом
Исследователи провели спектральный анализ, не имея доступа к закрытому кодеку Google. Они сгенерировали в Google Nano полностью черные и полностью белые изображения, нашли координаты частот, на которых держится водяной знак, и собрали их в словарь.
V1 — попробовали JPEG-сжатие с качеством 50%. PSNR — 37 дБ, фаза ухудшилась всего на 11%. Не сработало.
V2 — применили несколько преобразований подряд. PSNR упал до 27–37 дБ, но результаты были нестабильными.
V3 — перешли к спектральному вычитанию на нескольких масштабах. Здесь и случился прорыв: PSNR поднялся выше 43 дБ, SSIM — 0,997. На глаз картинка не отличалась от исходной. Согласованность фазы на нужных частотах упала на 91%. Иными словами, удалось стереть 9 из 10 водяных знаков.
Как обходят текстовые водяные знаки
Взламывать тексты еще проще:
Обратный перевод. Текст переводят на другой язык и возвращают обратно. После такой обработки точность распознавания резко падает.
Переписывание другой моделью. Если пропустить текст из Gemini через Claude или GPT-5, водяной знак исчезает, потому что новая модель пишет по-своему, с другим распределением вероятностей.
Ручная правка. Если заново выстроить фразы и изменить структуру текста, детектор заметно теряет уверенность.
Водяной знак — не абсолютная защита. Пока что любые попытки крупных компаний незаметно пометить контент можно сбить простым открытым скриптом на Python. Технических средств распознавания здесь мало, и Google придется искать что-то еще.
Отметим, что не стоит строить стратегию вокруг попыток спрятать AI-контент. В режиме ИИ Google важнее не то, удастся ли обойти метку, а то, сможет ли материал стать надежным источником ответа. Массовый слабый текст может проиграть даже без технической метки, а качественный материал с участием ИИ может ранжироваться и цитироваться нормально.
C2PA и Content Credentials: другой способ показать происхождение контента
Наряду с SynthID развивается и C2PA (Coalition for Content Provenance and Authenticity). Но работает этот стандарт совсем иначе.
Как работает C2PA
C2PA не пытается угадать, создал ли материал ИИ. Он прикрепляет к файлу своего рода паспорт: кто его сделал, в какой программе, использовал ли нейросеть. Этот набор данных называется Content Credentials — цифровое удостоверение происхождения и подлинности.
Кто уже внедряет стандарт
В коалицию входят более 200 организаций, среди них Adobe, Google, Microsoft, OpenAI, Meta, BBC, Amazon и Sony. А инициатива Content Authenticity Initiative (CAI) объединяет свыше 6000 участников — в том числе Nikon, Canon, Leica, Reuters и The Wall Street Journal.
В декабре 2025 года вышла версия C2PA 2.3: она добавила поддержку потокового видео через CMAF. Google встроил C2PA в результаты поиска. Pixel 10 поддерживает C2PA из коробки и имеет высший уровень защиты в программе сертификации — Assurance Level 2.
Чем C2PA отличается от SynthID
SynthID отвечает на вопрос: «Это сделал ИИ или нет?». C2PA отвечает на другой: «Кто создал файл и что с ним делали потом?».
Ограничение C2PA
У C2PA есть уязвимость, его метаданные можно удалить. Для этого достаточно пересохранить файл без меток, сделать скриншот или перевести файл в другой формат. Поэтому Google использует обе системы сразу: SynthID — как встроенную метку, а C2PA — как внешний сертификат происхождения.
Для владельцев сайтов C2PA может стать частью доверия к контенту, особенно если речь идет об изображениях товаров, медиа, новостях, медицинских материалах, финансах и других темах, где важно происхождение данных. Но сам по себе стандарт не может заменить E-E-A-T, редактуру и экспертную проверку.
Детекторы AI-контента: что умеют сторонние сервисы
Специалисты по SEO часто проверяют тексты в сторонних сервисах. Посмотрим, на что эти сервисы действительно способны.
Что обещают разработчики и что показывают независимые тесты
Originality.ai обещает точность 96–100%, Winston AI — 99,98%, GPTZero — 99,3%. Copyleaks заявляет, что у него меньше всего ложных срабатываний — 3%.
На деле все скромнее. Независимые исследования показывают точность 65–88% — в зависимости от модели, языка и того, как сильно правили текст. В исследовании 2023 года проверили 14 популярных детекторов, и ни один не дотянул до 80%. OpenAI через несколько месяцев после запуска вообще отозвала свой классификатор.
Проблема в том, что такие сервисы не понимают ни язык, ни стиль. Они ищут статистические совпадения, а они бывают и в текстах нейросети, и в статьях авторов-людей.
Получается, что детекторы AI-контента годятся только как грубый ориентир. Ни один сервис не может уверенно сказать, кто написал текст — человек или ИИ, если текст хотя бы немного отредактировали.
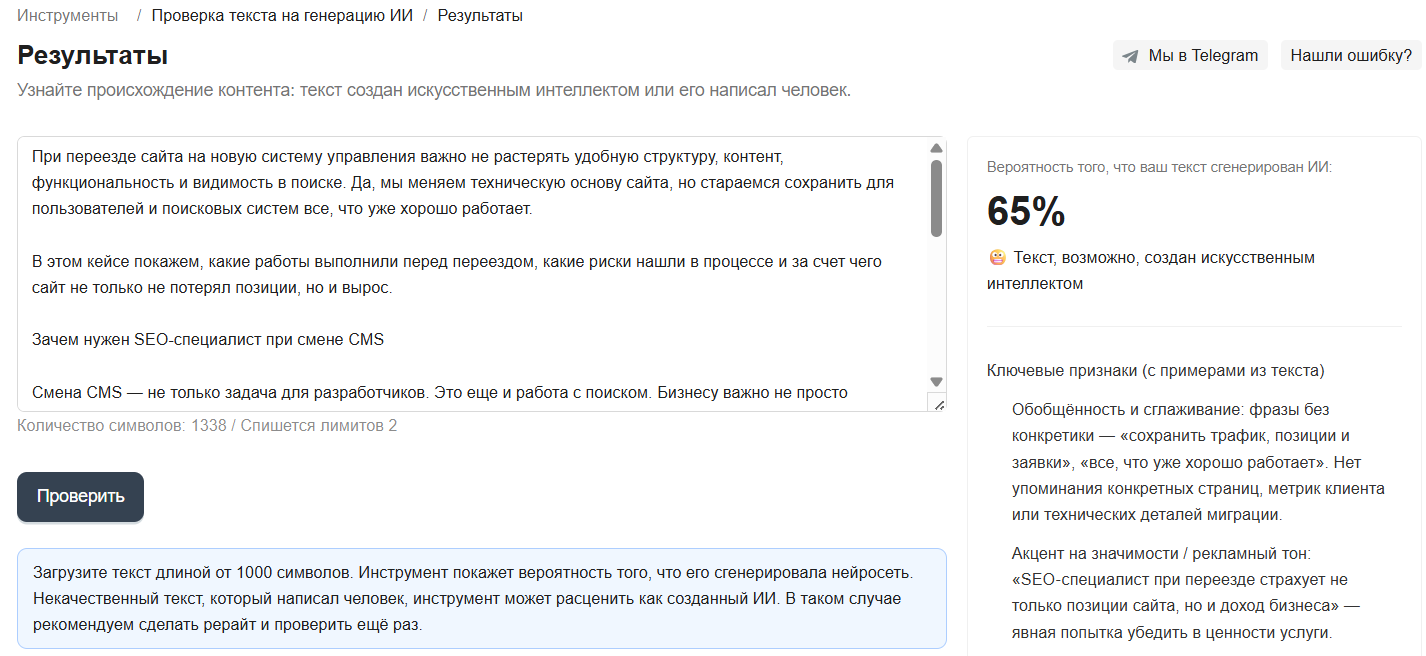
Поэтому проверку через детектор лучше использовать только как повод перечитать текст: убрать шаблонные фразы, добавить конкретику, экспертные комментарии, примеры, источники и собственные данные. Именно эти элементы помогают странице выглядеть надежной и для обычного поиска, и для режима ИИ Google.
Позиция Google: разрешает ли поисковик использовать AI-контент в обычной выдаче и режиме ИИ
В 2025–2026 годах Google ясно обозначил свою позицию по материалам, созданным с помощью ИИ. Все проще, чем кажется.
Материалы, созданные с помощью AI, разрешены
Google прямо говорит, что если материал полезен людям, способ его создания неважен. Важно не то, написал его человек или нейросеть, а то, что в итоге получил читатель.
Этот подход распространяется и на новую поисковую среду: для AI Overviews и режима ИИ Google важно, чтобы источник был полезным, точным, проверяемым и заслуживал доверия. Сам факт использования нейросети не делает страницу плохой, но и не дает ей преимущества.
Массовый выпуск бесполезного контента под запретом
Google запрещает штамповать материалы без пользы для читателя. Это то, что компания называет Scaled Content Abuse. С июня 2025 года поисковик начал вручную наказывать сайты, которые публиковали сотни сгенерированных статей в день без редакторской проверки.
После мартовского обновления основного алгоритма в 2026 году борьба с таким потоком стала одной из главных задач. Сайты, которые выпускали по 50–500 сгенерированных статей в день без проверки человеком, потеряли от 40 до 90% посещаемости.
Слабые страницы могут не только просесть в органике, но и не попасть в список источников для генеративных ответов. Если материал не добавляет новой информации, не подтверждает факты и не показывает экспертность, меньше причин использовать его в режиме ИИ Google.
E-E-A-T по-прежнему важен
Experience, Expertise, Authoritativeness, Trustworthiness (опыт, знания, авторитет и надежность) по-прежнему в центре внимания. Для материалов, созданных с помощью ИИ, эти требования даже важнее, потому что они отделяют полезный текст от бессмысленного спама.
Почитать по теме: Факторы E-E-A-T Google и три чек-листа для проверки сайтов
Дополнительное требование для e-commerce
Google обязал интернет-магазины помечать изображения товаров, созданные нейросетью, через метаданные IPTC. Дело в том, что в режиме ИИ Google может сравнивать товары, объяснять различия, подбирать варианты под запрос пользователя и использовать изображения, карточки и характеристики. Если визуальный контент создан нейросетью, лучше не скрывать это.
Позиция Яндекса
Яндекс идет тем же путем, что и Google, но по-своему. Весной 2025 года Яндекс обновил алгоритмы и сделал упор на ценность контента. Система научилась распознавать тексты, написанные ИИ, даже если их слегка переписали.
Тексты с водой, кликбейтные заголовки, попытки выдать себя за официальный источник, высокий процент отказов — все это может понизить сайт в выдаче. Здесь есть и противоречие: Яндекс наказывает за слабый AI-контент, но сам активно продвигает нейроответы через сервис «Алиса AI».
С марта 2025 года Яндекс использует разметку Schema.org, чтобы оценивать авторов. Если на сайте нет сведений об авторе, дате публикации и источниках, шансов попасть в топ меньше.
Правила у Яндекса во многом похожи на правила Google, но как именно он распознает такой контент, компания почти не объясняет. О технологиях, подобных SynthID, Яндекс не рассказывает, зато сильнее опирается на поведенческие сигналы и признаки качества.
Как оптимизировать контент под AI Mode
Мы разобрались, как Google распознает контент, созданный с помощью AI, и почему поисковику важно качество исходных данных. Теперь — к делу: как работать с контентом, чтобы не терять позиции и повышать шансы попасть в источники AI Mode.
Используйте ИИ как помощника, а не вместо автора
Использование ИИ для генерации текстов не запрещено поисковиками, однако важно учитывать несколько факторов.
1) Контент должен нести добавочную ценность — каждая новая статья должна не только пересказывать уже ранее написанную информацию в интернете, но и вносить нечто уникальное. Это могут быть собственные исследования, комментарии экспертов, кейсы, блок FAQ, реальные примеры использования — все то, что не только позволяет уникализировать контент для ИИ, но внести реальную ценность для читателя.
2) Проработка ЕЕАТ — реальное авторство является дополнительным сигналом, что контент либо написан экспертом, либо промодерирован им. Также стоит ссылаться на прочие авторитетные источники, указывать список литературы (особенно для тематики YMYL) и использовать только реальных экспертов.
Современная методика копирайтинга контента уже тоже во многом отошла от старых способов написания статей. Если раньше контент от и до писал копирайтер-эксперт, то сейчас копирайтеры часто используют в написании текстов ИИ как помощников — но ключевое правило осталось тем же — качество контента.
Важно понимать, что ИИ это в первую очередь помощник, а не решение. Поэтому само наличие процента ИИ-текста в статьях не является чем-то плохим. Другое дело если весь контент (или большая часть) на сайте сгенерирован ИИ и не несет добавленной ценности для читателя. Такие сайты рискуют полностью потерять позиции в поисковой выдаче, как это было с апдейтом Гугла в начале 2025 года.
Иван Сиваков, Senior SEO компании WSS. Специалист в области E-commerce, Fintech, Medicine, AIO.
Добавляйте свои данные
Исследование Принстонского университета показало, что если в тексте есть оригинальные элементы, ИИ-системы цитируют его заметно чаще:
статистика и собственные данные — +40% к видимости;
ссылки на источники — +30-40% к цитируемости;
комментарии экспертов — +28% к охвату аудитории;
сочетание нескольких элементов — еще +5,5% к результату.
Проверьте плотность ключевых слов и общую оптимизацию, а потом усильте текст живыми данными: цифрами, ссылками на источники и примерами из практики.
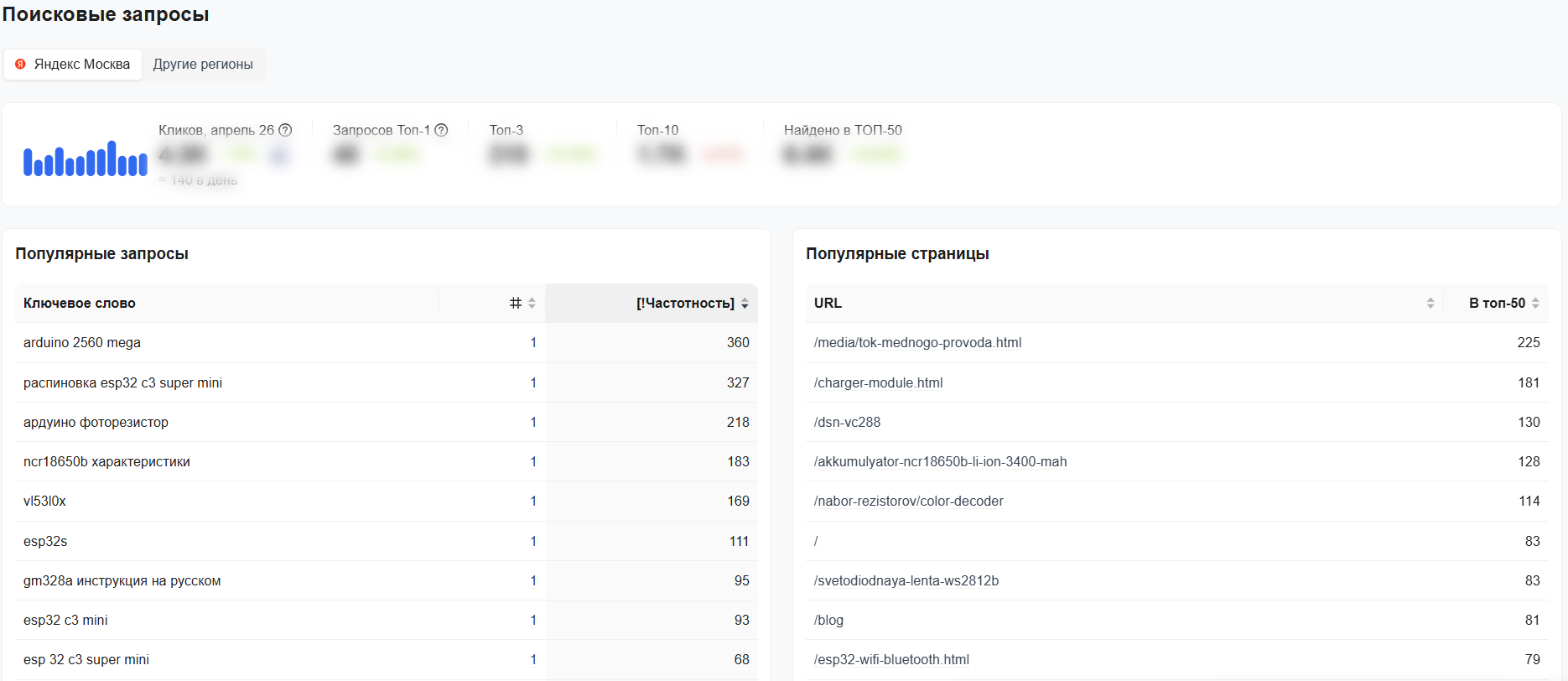
Покажите, кто автор
Подписывайте статьи именем автора, делайте страницы с краткой биографией и ставьте ссылки на его профессиональные профили. Для Google это признаки E-E-A-T. Тексты с настоящим автором обычно ранжируются лучше, чем анонимные, независимо от того, писал их человек сам или с помощью ИИ.
Проверяйте и улучшайте тексты AI-инструментами
Перед публикацией пропустите текст через инструменты для редактирования, которые помогают убрать канцелярит и сделать текст живее. От тщательной редактуры выигрывает любой текст.
Чек-лист: как подготовить страницу к AI Mode
| Что проверить | Зачем это нужно |
|---|---|
| Есть прямой ответ на главный вопрос | AI Mode проще использовать страницу как источник |
| Структура понятна по H2 и H3 | Поиску легче выделить смысловые блоки |
| Есть определения, списки и таблицы | Фрагменты удобнее цитировать в ИИ-ответах |
| Факты подтверждены источниками | Повышается доверие к материалу |
| Указаны автор и эксперт | Усиливается E-E-A-T |
| Есть дата публикации и обновления | Видна актуальность данных |
| Добавлены уникальные примеры или опыт | Страница отличается от пересказа конкурентов |
| Нет массовой генеративной воды | Снижается риск попасть под фильтры качества |
| Используется корректная Schema.org | Поисковику проще понять сущности |
| Есть внутренние ссылки | Улучшается связность сайта |
| Есть внешние упоминания бренда | Повышается авторитет источника |
| Материал обновляется | Контент остается актуальным |
Заключение
Распознавание материалов, созданных AI, похоже на войну антивирусов с вирусами. SynthID ломают, метки C2PA стирают, а распознаватели обходят простой правкой текста. Google помечает свой контент через SynthID, подтверждает источник с помощью C2PA и отдельно проверяет качество материала. Но ни один из этих способов сам по себе не дает полной защиты.
Если обратить внимание на то, как Google распознает материалы AI, видно, что поисковик смотрит не на происхождение текста, а на его пользу. Полезный ИИ-материал, который эксперт лично дополнил и отредактировал, Google может поставить в выдаче не ниже текста, написанного человеком, а иногда и выше. И чем больше интернет заполняют однотипные тексты от ИИ, тем выше Google будет ценить живые, содержательные материалы.
Борьба с детекторами AI-текстов — это борьба со следствием. Причина глубже: алгоритмы окончательно переходят от поиска по строкам к поиску по Сущностям (Entities). В эпоху GEO (Generative Engine Optimization) выигрывает не тот, кто пишет тексты на 100% руками, а тот, кто делает свой контент приоритетным источником для обучения LLM-моделей.
Уникальные данные, цифры и опыт эксперта критически важны. Нейросети боятся собственных галлюцинаций, поэтому алгоритмы всегда ищут твердые факты (пруфы, исследования, статистику), чтобы на них опереться. Запомните: фактологическая точность сегодня стоит в сто раз дороже, чем лингвистическая уникальность.
Василий Жарков, Founder & Head of AiSEO: NeuroReach, идеолог стандарта продвижения в нейросетях и монополизации брендов в ИИ.
FAQ
Что такое режим ИИ?
Это формат поиска, в котором нейросеть формирует готовый ответ на запрос пользователя и может показывать источники, уточнения, карточки и дополнительные материалы.
Чем режим ИИ отличается от обычного поиска?
Обычный поиск показывает список ссылок, а режим ИИ сразу собирает ответ из нескольких источников и позволяет уточнять вопрос в диалоговом формате.
Что такое AI Mode в Google?
AI Mode — это отдельный ИИ-интерфейс поиска Google на базе моделей Gemini.
Чем AI Mode отличается от AI Overviews?
AI Overviews появляются внутри обычной выдачи как краткий ИИ-обзор, а AI Mode работает как отдельный поисковый интерфейс с диалогом и развернутыми ответами.
Есть ли аналог режима ИИ Google в Яндексе?
У Яндекса нет полного аналога в том же виде, но похожие задачи решают Алиса AI, нейроответы и ИИ-функции поиска.
Как сайту попасть в ИИ-ответы Google?
Нужно давать прямые ответы, подтверждать факты источниками, указывать автора, добавлять экспертные комментарии, структурировать текст и регулярно обновлять материал.










