
Начинать читать лучше после ознакомления с первой частью интервью по этой ссылке.
А как тогда сегодня обстоят дела с небольшими сайтами? В прошлом, как известно, часто звучали призывы к владельцам авторских веб-проектов ежедневно наполнять их контентом. В итоге в сети появилось множество блогов с весьма сомнительным содержанием. О кофе, который я пью, о бананах, которые ем, и прочем в таком же духе.
И вот блогер одумался, решив, что низкопробного, проходного контента больше не будет. Владелец сайта даже готов оптимизировать его, закрыв для индексации те старые посты, которые никогда никого не интересовали. Как в таком случае поведет себя Google – по-новому оценит общее качество проекта? Или вашему поисковику не интересны такие изменения и он будет концентрировать свое внимание на новом контенте?
Джон: Мне кажется, что использование noindex для старого контента в этом случае не принесет каких-либо заметных изменений, особенно если у вас на сайте достаточно качественных материалов. Рассмотрим пример сайта газеты. Ежедневно такой ресурс публикует, скажем, двадцать новостей. Спустя неделю девятнадцать из этих материалов объективно утрачивают свою релевантность. Впрочем, это не означает, что такой неактуальный контент нужно непременно закрывать от индексации. Достаточно перенести его в архив. Избавляться полностью от него не нужно.
Ясно. А не могли бы вы тогда рассказать, как именно Google оценивает качество ресурса? Какой тип контента вы считаете высококачественным? Используете ли вы алгоритм BERT, чтобы лучше разбираться в качестве контента?
Джон: Вряд ли этот вопрос ко мне, поскольку я отвечаю не совсем за это. Про BERT могу подтвердить – это алгоритм, который позволяет Google лучше разбираться в контенте. Не столько в его качестве, сколько в том, о чем он. Про что это предложение или поисковый запрос, какие связи между ними существуют и т.д.
И вот тут, скорее всего, мы подходим к пониманию качества контента. Иногда манера изложения такова, что мы не можем правильно понять, что именно хотел сказать, донести до целевой аудитории автор. В такой ситуации BERT в какой-то мере признает свое бессилие. Не потому, что анализируемый контент плох, а потому что алгоритм не знает, что с ним делать дальше.
Это показательно в случае с SEO-копирайтингом, когда автор наполняет предложения огромным количеством ключевых слов и их синонимов. В итоге появляется текст, который и текстом-то в нормальном смысле слова назвать нельзя. Какая идея в нем первостепенна, о чем речь вообще, на чем сделать главное ударение? BERT не знает ответа.
Спасибо, следуем дальше. Допустим, есть торговая площадка, где на странице с товаром в самом низу присутствует огромный SEO-текст. По сути, это простыня текста с обилием ключевых слов, созданная сугубо для поисковых роботов. Покупатели онлайн-магазина вряд ли когда-либо обращают внимание на такой нечитабельный контент. Как поступит BERT в такой ситуации? Попробует разобраться, на какие поисковые запросы такая страница отвечает лучше всего? Или просто умоет руки, а Google в целом примет решение, что этот URL-адрес переоптимизирован ключами, а потому должен быть понижен в выдаче?
Джон: Мне не часто приходится видеть такое, но очевидно, что речь идет о чрезмерном насыщении текста ключевыми словами. Обнаружив подобное, наши алгоритмы быстро поймут, что перед ними не статья из Википедии, а бессвязный текст, напичканный ключевиками. К чему это приведет? Будет принято решение весьма осмотрительно подходить к ранжированию такой страницы.
А вообще, любителям такой неудачной SEO-оптимизации я бы посоветовал следующее. Сегодня в сети достаточно информации о том, как устроены в том числе и наши алгоритмы по оценке текста. Есть даже готовые инструменты проверки. Возьмите и протестируйте свой переоптимизированный ключами текст с их помощью. Попробуйте узнать, по силам ли алгоритмам разобраться в содержании такого спамного контента? Вряд ли после этого вы будете использовать подобные методики продвижения.
BERT способен понимать смысл текста не только на странице, но и в самом поисковом запросе, правда?
Джон: Совершенно верно.
Тогда такой вопрос – что будет, если алгоритмы Google, проанализировав пользовательский запрос, определили, что он относится к числу коммерческих? Значит ли это, что вы автоматически по такому запросу будете ранжировать исключительно коммерческие сайты? Или в Google SERP все же останется место для информационных ресурсов?
Джон: На мой взгляд, в результатах поиска будут и те, и другие сайты. Все дело в том, что как бы хорошо не работали наши алгоритмы, как бы точно они не определяли поисковые запросы, всегда останется место для вариаций. Особенно если учесть, что ежедневно мы обрабатываем до 15% совершенно новых поисковых запросов, на которые у нас априори не может быть заготовленных ответов.
Давайте поговорим о дорвеях. Представим ситуацию, ко мне приходит клиент, бизнес которого оперирует в 50-100 городах. У этого человека дилемма. С одной стороны, ему нужна уникальная приветственная страница для каждого города. С другой, перечень услуг, которые он предоставляет, одинаковый для каждого города. Как посмотрит Google на то, что под каждый населенный пункт будет создана своя собственная страница, с которой и будет осуществляться переход к основному контенту? Или есть способ обойтись без дорвеев?
Джон: Я считаю, что дорвеев быть не должно. Конечно, может казаться, что вашему веб-проекту без них не обойтись, но если разобраться, то смысловая нагрузка таких страниц стремится к нулю. Несмотря на это, я допускаю, что иногда основной сайт и его дорвеи могут ранжироваться довольно высоко. Но не стоит забывать, что в один прекрасный момент наша команда, отвечающая за качество поиска, может обратить пристальное внимание на такие страницы.
Есть несколько вариантов выхода из описанной вами ситуации. Когда у компании есть представительства в разных городах, тогда в рамках основного сайта можно выделить отдельную страницу под каждый городской адрес с указанием графика работы в конкретном регионе. Или можно создать отдельную страницу, на которой будут собраны адреса всех городских представительств (по регионам), плюс использовать динамическую карту или что-то в этом роде.
Как часто сегодня вы наказываете сайты в ручном или автоматическом режиме за использование дорвеев?
Джон: Я не располагаю такой информацией.
Хорошо. В кругу сеошников есть устоявшееся мнение, что Google, когда обрабатывает поисковые запросы, связанные с финансами или здоровьем, в своей выдаче предпочтение отдает авторитетным YMYL-порталам, скажем, сайтам официальных брендов или ресурсам в доменной зоне .gov. В этой связи мои клиенты часто спрашивают – как небольшой сайт, который по текстовому и видеоконтенту превосходит официальные порталы, может на равных конкурировать с ними в результатах поиска Google? Я понимаю, что такие суждения субъективны, но что вы посоветуете владельцам небольших сайтов в этих нишах?
Джон: Убежден, что обойти в выдаче авторитетные порталы можно и ниша здесь роли не играет. В конце концов, позиции в поиске никто ни за кем не закрепляет. Ранжирование в конкретный период времени зависит от многих факторов, в том числе от тематики и уровня конкуренции. Главное, не думать, что обойти конкурентов можно с наскока, кое-как создав сайт и добавив на его страницы немного качественного контента.
И еще один совет – не нужно пассивно полагаться на время. Если хотите победить в конкурентной борьбе, работы по улучшению сайта нужно вести постоянно. Нельзя просто сидеть и успокаивать себя, мол, когда моему веб-проекту исполнится десять лет, он будет таким же авторитетным, как другие сайты этой ниши в этом возрасте. Это так не работает.
Также хочу подчеркнуть, что если речь идет о в самом деле хороших небольших сайтах, то им стоит ориентироваться на трафик не только из поиска. В сети достаточно других источников, которые могут генерировать большую посещаемость для таких ресурсов. То есть, нужно комбинировать, делать все возможное для развития сайта в поиске Google и за его пределами.
Со своей стороны мы всегда будем ранжировать эти ресурсы в названных нишах. Другой вопрос – как высоко? Достаточно, если веб-мастер сможет обеспечить пользователям контент соответствующего качества, релевантности и правдивости, чтобы на равных конкурировать с правительственными сайтами. Сделать это нелегко, но можно.
И все-таки очень бы хотелось знать точный ответ, как обойти их в поиске? Скажем, я разработала собственную диету, с помощью которой добилась прекрасных индивидуальных результатов. Теперь я посредством специально созданного сайта хочу поделиться успешным опытом похудения с другими людьми. Однако на первой странице выдачи Google по нужным мне запросам давно обосновался сайт клиники Мэйо и какой-то официальный государственный ресурс. Есть ли какие-то конкретные подсказки, что нужно предпринять в первую очередь? Можно представить, что я не ограничена в ресурсах и готова на любые эксперименты, лишь бы обойти эти авторитетные сайты в Google SERP.
Джон: К сожалению, у меня нет готового ответа на подобие – вам нужно выступить по национальному ТВ или попасть в Wikipedia. Каждый конкретный случай уникален сам по себе, потому невозможно посоветовать что-то универсально эффективное.
Понимаю и признаю, что мой вопрос был несколько провокационным. Просто к нам часто приходят клиенты с требованием добиться доминирования в определенной нише и бюджеты их не интересуют. Они готовы раскошелиться на любую сумму.
Тогда напоследок еще один интересный пользовательский кейс. У нас есть клиент, чей сайт стал примером низкокачественного ресурса в вашем руководстве Google’s Quality Raters Guidelines. Скриншот страницы этого сайта, который вы демонстрируете до сих пор, на самом деле уже устарел. Ребята хорошо потрудились и исправили ошибки. Теперь через меня они хотят узнать, как сделать так, чтобы их проект больше не использовался вами в таком негативном контексте? Это вредит репутации их бренда.
Джон: Я готов с радостью помочь в этой ситуации, если вы предоставите мне конкретные примеры. Также хочу обратить внимание на то, что для пользователя истинность этого руководства не является абсолютной. Иначе говоря, если мы показали в нем конкретный URL-адрес в определенном контексте, то это не значит, что впредь вы всегда должны равняться только на эту страницу, стремясь быть похожей или не похожей не нее.
На этом все самое интересное и познавательное от Джона Мюллера в подкасте закончилось. Но мы, как и обещали в первой части, приготовили небольшой бонус. Уже после беседы с Мари Хейнс в Твиттере был запущен опрос: «Вы слепо доверяете Джону Мюллеру?» Результаты выглядят так:
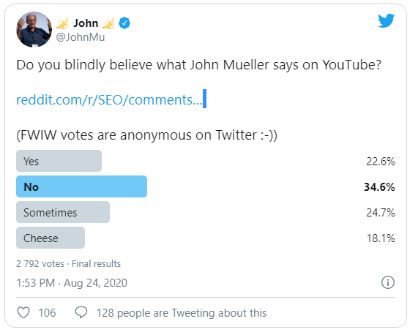
В исследовании приняли участие почти 2,8 тыс. сеошников и веб-мастеров. Большинство из них (34,6%) ответили отрицательно. Утвердительных ответов было 22,6%. Чуть больше оказалось тех, кто верит Гуглмену время от времени – 24,7%. Были также весельчаки (18,1%), которые из всех вариантов выбрали шутливую опцию про сыр...
А к какой группе принадлежите вы? Слова Джона в этом интервью заслуживают внимания? Поделитесь своим мнением в комментариях.







