
Разработчики Яндекса научили свою нейросеть переводить видео с китайского на русский. Технология уже работает на YouTube, а в ближайшее время в Браузере появится интеграция с китайским сервисом Bilibili. Также разработчики в частном порядке могут помочь с переводом видео на конкретных сайтах. Для этого необходимо связаться с ними по почте suggest-site@support.yandex.ru.

Как обучалась нейросеть
Китайский по праву считается одним из сложнейших языков мира. Во-первых, он состоит из множества диалектов, которые отличаются между собой настолько радикально, что жители разных регионов могут не понимать друг друга. Во-вторых, он обладает языковыми особенностями, например, произношения, которые усложняют задачу распознавания речи роботами. А еще в китайском языке существуют тоны – это повышение или понижение высоты голоса во время произнесения слогов, которые также влияют на смысл произносимого.
Разработчики решили начать с самой распространенной формы – севернокитайскомго языка, также известного как мандаринское наречие. Им владеет почти 70% населения Китая (порядка 1 млрд человек). В нем около 400 основных слогов и четыре тона. Самым сложным в порядке работы на начальном этапе для разработчиков стала первоначальная выборка для обучения, поскольку готового датасета для китайского языка у них просто не было.
Как создавалась выборка
Чтобы привести данные в нужный вид, и отсеять мандаринский от остальных диалектов, а также определить валидность проверяемых данных, разработчики установили следующий алгоритм работы:
В качестве источников выбрали несколько тысяч часов видео, содержащих китайские субтитры.
При помощи классификатора отсеяли видео не на китайском языке (многие видео на английском языке содержат китайские субтитры).
Достали голосовые куски на основе субтитров в формате VTT (содержит все фразы с таймкодами). Нормализовали звук при помощи готовой библиотеки.
Нарезали видео на куски в соответствие с субтитрами.
Отфильтровали видео по субтитрам. Чтобы установить валидность сказанного и написанного применяли обученную на мандаринском модель с Hugging Face.
На выходе получили набор с качественными и корректными субтитрами.
В получившийся датасет попала выборка из 100 тысяч видео (из полутора миллиона изученных).
Как определили тон (не Toncoin)
Для установления произношения, Яндекс изучил, как выглядит мелодика голосов в зависимости от тона по инфографике. Поскольку, тон определяется высотой, визуально определить каждый из них оказалось не так сложно. Например, первый – произносится ровно и высоко, а четвертый – нисходящий.
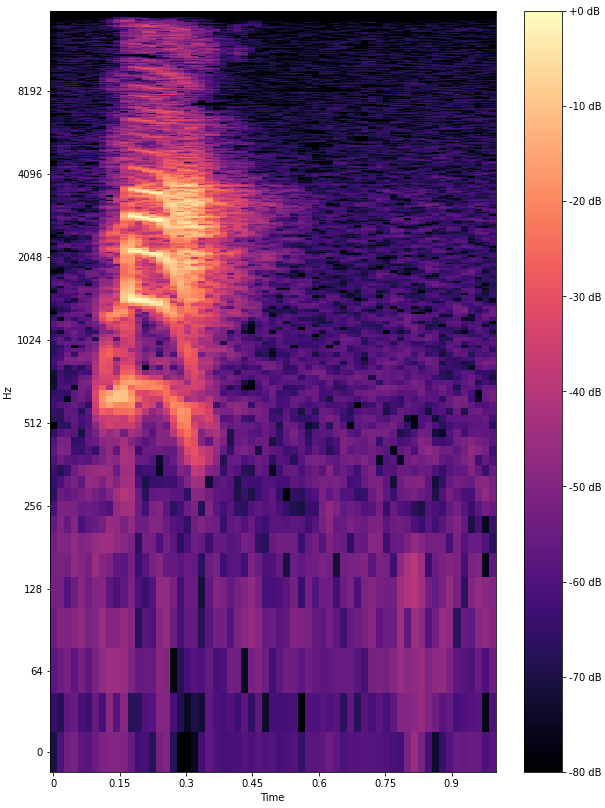
Модель сама научилась распознавать тоны по обучающим данным. По словам разработчиков, система собрала за месяц объем данных, которые специалисты-китаеведы способны изучить за 20 лет непрерывной практики.
Как работает перевод
Чтобы вмонтировать технологию в уже существующую, перевод с китайского на русский работает с промежуточным этапом – через английский язык. Разработчикам пришлось отдельно учесть пунктуационные особенности языком, чтобы не терять смысловые окончания по пути. Для этого они создали гибридный «пунктуатор»: он устанавливает запятые по правилам китайского языка, но выделяет смысловые части в целые предложения.
Подробнее о новой технологии читайте на Хабре.
Напоминаем, что впервые технологию по автоматическому закадровому переводу видео в своем Браузере Яндекс представил еще осенью 2021. С тех пор в нем появились интерактивные субтитры на четырех языках, а также синхронный перевод стримов.






