
Содержание
Успешная индексация нового сайта складывается из многих элементов. Один из них — файл robots.txt, содержащий информацию для поисковых роботов.
Что такое Robots.txt
Файл robots.txt — это текстовый документ, который содержит инструкции по видимости сайта для поисковых ботов. Он указывает поисковикам, какие страницы ресурса нужно просканировать, а какие — исключить из этого процесса. Это помогает распределить активность поисковых роботов: вы запрещаете им тратить время на закрытую или неактуальную информацию, чтобы вместо этого роботы сосредоточились на ключевых страницах, важных для вашего SEO.
Команды внутри robots.txt влияют именно на сканирование (краулинг), от которого, в свою очередь, зависят результаты индексации — добавления информации о вашем сайте в базу данных поисковика. Поэтому работа с этим механизмом требует большой осторожности и понимания дела. Корректно заполненный файл — залог хорошей видимости сайта, но некоторые ошибки могут «убить» индексацию или навредить конфиденциальности информации на ваших страницах.
Мы составили этот гайд для того, чтобы развеять популярные заблуждения и предложить актуальные советы по работе с robots.txt.
Зачем нужен robots.txt
Каждый поисковик составляет свой собственный индекс — огромную базу того, какие страницы существуют в интернете. Для этого они используют поисковых роботов, которые переходят по ссылкам и собирают информацию о том, что находят. Из этих данных формируется то, что мы видим в результатах поиска в Яндексе или Google.
Сканирование сайта требует времени и ресурсов, к тому же этот процесс может быть довольно хаотичным. Без инструкций роботы сами выбирают, в каком порядке посещать страницы, из-за чего сначала может быть обработана статья четырехлетней давности, а свежие новости и актуальные контакты — значительно позже.
Поэтому при заходе на сайт роботы ждут особых инструкций — как раз они и содержатся в robots.txt. С помощью этого файла можно повлиять на ход сканирования и направить алгоритмы по нужному вам пути. Обычно это делается с помощью запрета на посещение определенных страниц или разделов — тогда ресурсы поисковиков будут направлены на изучение того, что не заблокировано.
При помощи robots.txt можно:
Заблокировать сканирование определенных ссылок. Можно помешать роботам видеть HTML-страницы, медиафайлы и файлы ресурсов (например, стили и скрипты).
Переместить внимание поисковиков на важные страницы. Закрытые страницы не будут отвлекать роботов от информации, которая должна попасть в поиск.
Разрешить сканирование сайта только определенным роботам. Это позволяет снизить нагрузку на сервер и контролировать трафик.
Указать расположение sitemap.xml. Карта сайта подскажет роботам актуальный состав страниц и поможет оптимизировать их работу.
Ограничения robots.txt
Содержание robots.txt часто называют рекомендациями для поисковых роботов. Важно понимать, что этот механизм не дает вам полный контроль над поисковой выдачей:
robots.txt не гарантирует стопроцентной блокировки индексации. Этот метод запрещает прямое сканирование, но роботы могут попасть на ту же страницу, если на нее ссылаются другие источники. В таком случае ссылка все же может оказаться в поиске, хотя и без полноценного описания в сниппете и, скорее всего, далеко от верхних позиций. В первую очередь это нужно учитывать, когда вы работаете с персональными данными и другой чувствительной информацией.
Не все поисковые роботы проверяют robots.txt перед заходом на сайт. Это значит, что инструкции в файле не повлияют на сканирование со стороны некоторых краулеров от Google и Яндекс и ряда других поисковиков.
Чтобы избежать потенциальных проблем, стоит использовать более широкий комплекс технических средств. Ниже мы разберем, для каких задач robots.txt будет достаточно, а для каких потребуются дополнительные этапы.
Файл robots.txt — название и расположение
Для начала разберемся с тем, как подготовить сам файл. Для работы подойдет стандартное приложение Блокнот — просто создайте новый текстовый документ и задайте ему имя. Он должен называться robots.txt и никак иначе. Алгоритм чувствителен к регистру, поэтому в названии не должно быть больших букв и посторонних символов.
Разместить robots.txt нужно в корневом каталоге сайта, например: https://site.com/robots.txt. Приходя на сайт, поисковые роботы проверяют эту директорию и ожидают увидеть здесь файл с корректным названием, передающий HTTP-ответ с кодом 200 OK. Если этого не происходит, сканирование происходит в произвольном режиме, даже если правильные инструкции лежат где-то в другом месте.
Действие robots.txt распространяется на тот домен, на котором он расположен. Правила из файла по адресу https://site.com/robots.txt будут действовать на site.com, но не на m.site.com — для поддомена потребуется свой собственный документ.
Размер самого файла не должен превышать 500 КБ, иначе Яндекс его не увидит. А вот Google способен работать и с более тяжелыми файлами, но перестанет воспринимать любые команды, которые выходят за рамки указанного объема.
Не всегда robots.txt нужно создавать самостоятельно. Многие конструкторы сайтов формируют его автоматически, а от вас требуется только наполнить его содержимым. Еще чтобы написать robots.txt, можно воспользоваться онлайн-инструментом: генератор создаст файл за пару минут.

Как заполнить robots.txt
Внутри самого файла располагаются правила (так их называет Google) или директивы (такое слово использует Яндекс), которые считывают поисковые роботы. С их помощью можно установить разрешение или запрет на сканирование страниц для всех или отдельных роботов, а также указать некоторые другие параметры. Обратите внимание — Яндекс поддерживает на одну директиву больше, чем Google.
Правило (директива) | Описание | Яндекс | |
User‑agent | Указывает, для каких роботов прописаны инструкции | ✔ | ✔ |
Disallow | Запрещает сканирование указанных страниц или каталогов сайта | ✔ | ✔ |
Allow | Разрешает сканирование указанных страниц или каталогов сайта | ✔ | ✔ |
Sitemap | Задает путь до карты сайта (sitemap) | ✔ | ✔ |
Clean-param | Указывает на дополнительные параметры ссылки, которые не нужно учитывать при сканировании | ❌ | ✔ |
User‑agent
Это правило указывает, для каких поисковых роботов действуют правила, следующие далее. С помощью значения * можно указать параметры для всех основных поисковых роботов, которые занимаются сканированием для индексации.
Важно: в этот список входят не все существующие боты, а некоторые краулеры и вовсе игнорируют robots.txt. Посмотреть списки специальных роботов-исключений можно в справках Google и Яндекс.
Вот пример того, как запретить сканирование сайта всем основным роботам, кроме Яндекса:
User-agent: * Disallow: / User-agent: Yandex Allow: /
Disallow
Disallow запрещает роботам сканировать страницы по указанному адресу или целый каталог. Чтобы робот правильно обработал ссылки, они должны быть указаны в корректном виде:
Страница — /page.html;
Каталог — /folder/;
Сайт целиком — /.
С помощью символа * можно указать все ссылки, содержащие определенные слова или форматы файлов. Например, так мы заблокируем для Google сканирование всех pdf на нашем сервере:
User-agent: Googlebot Disallow: /*.pdf
А так мы исключим из сканирования в Яндексе все, что содержит слово category:
User-agent: Yandex Disallow: /*category*
Allow
Выполняет обратную Disallow функцию — разрешает сканирование страницы. Нет смысла добавлять сюда все, что вы хотите показать роботам, ведь в таком случае robots.txt станет слишком большим по объему. К тому же краулеры и так сканируют все, что не запрещено. Основная роль Allow — в том, чтобы создавать исключения из уже указанных правил.
Важно: для Allow действуют те же правила форматирования и написания ссылок, что и для Disallow.
Так, например, можно запретить Google сканировать весь сайт, кроме блога:
User-agent: Googlebot Allow: /blog/ Disallow: /
Sitemap
С помощью этой строки можно указать путь до карты сайта в файле sitemap.xml. Ссылку на него надо указать целиком, например:
Sitemap: https://site.com/sitemap.xml
Clean-param
Роботов Яндекса можно заставить игнорировать дополнительные параметры ссылок, чтобы не тратить ресурсы сервера на дублирующийся контент и исключить его из поиска.
Например, у нас есть каталог с разными параметрами сортировки:
site.com/catalog/category/?sort_field=price&order=asc (сортировка по цене)
site.com/catalog/category/?sort_field=price&order=desc (сортировка по цене в обратном порядке)
site.com/catalog/category/?sort_field=name&order=asc (сортировка по названию)
Чтобы избавиться от этих параметров и привести сканируемый URL к единому виду, нужно передать Яндексу инструкцию, в которой будут указаны лишние элементы:
User-agent: Yandex Clean-param: sort_field&order /catalog/category/
А чтобы директива работала для всего сайта, не указывайте адрес ссылки — просто пропишите требуемые параметры.
Важно: Это правило не работает в Google. На замену ему предлагают использовать Disallow: /*?*. Но у такого метода есть свои риски — не просканированные ссылки с параметрами теряют вес, если их использует сторонний источник. Чтобы все работало правильно и ссылочная масса накапливалась корректно, рекомендуется добавить каждому дублю метатег rel=”canonical”.
Подпишитесь на нашу рассылку — раз в неделю будем отправлять на ваш email свежую статью из блога и другие полезные материалы.
💌 Еженедельная рассылка
Важные правила при работе с robots.txt
Существует пара моментов, от которых зависит, смогут ли роботы правильно считать содержание robots.txt.
Используйте только латиницу
Весь текст в robots.txt должен быть прописан латиницей. При работе с кириллическими ссылками не забудьте перевести их в нужный формат — например, с помощью Punycode-конвертера.
Неправильно: сайт.рф
Правильно: xn--80aswg.xn--p1ai
Соблюдайте корректную структуру
Роботы читают инструкции сверху вниз и объединяют их в группы, которые указывают, что нужно сделать. Каждая группа правил должна содержать как минимум по одной строке User-agent и Disallow или Allow — без этого условия значения User-agent объединяются.
В этом примере есть серьезная ошибка:
User-agent: * Sitemap: https://site.com/sitemap.xml User-agent: Googlebot Disallow: /
Мы указали sitemap для всех поисковых роботов, но это не будет разрешающей или запрещающей командой. Из-за этого правила User-agent объединяются в единую группу, а это значит, что сканирование сайта окажется закрыто не только для Googlebot, но и для всех остальных поисковиков.
Одна ссылка — одно правило
Нельзя указывать разные адреса через запятую или другие символы. Каждая ссылка должна быть оформлена в собственное правило, например:
User-agent: * Allow: /blog/ Allow: /news/ Disallow: /
Как надежно закрыть страницу от индексирования
Правила в robots.txt касаются сканирования страниц. Запрет на сканирование означает, что поисковые роботы не соберут закрытую информацию при посещении вашего сайта, но это не помешает им узнать о существовании страницы другими способами.
Если любой другой открытый для сканирования источник ссылается на страницу, которую вы заблокировали через robots.txt, она все-таки попадет в индекс. При этом у нее будет сокращенный сниппет — без доступа к контенту поисковику неоткуда взять описание.
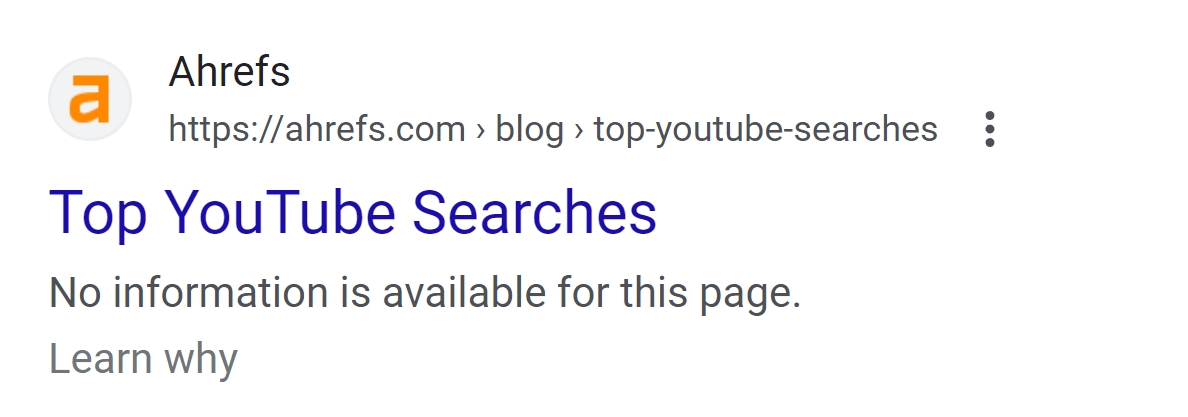
Чтобы не случалось непредвиденных ситуаций, используйте проверенные методы для полноценного удаления страницы из выдачи. Подробнее о них можно узнать в справочниках Яндекс и Google.
Метатеги страниц и HTTP-ответов
В HTML-коде страниц можно прописать метатеги, которые укажут роботам правильное поведение. Закрыть страницу от индексирования поможет параметр noindex для тега Robots:
<meta name="robots" content="noindex">
Такой же параметр можно прописать на уровне заголовка HTTP-ответа с помощью X-Robots-Tag. Это работает как для страниц, так и для любых файлов на вашем сервере:
HTTP/1.1 200 OK (...) X-Robots-Tag: noindex (...)
Учтите, что для того, чтобы этот метод работал, роботы должны просканировать страницу. Это значит, что noindex не будет работать одновременно с Disallow в robots.txt — убедитесь, что страница разрешенная для посещения краулерами.
Теги
Яндекс позволяет запретить индексацию части текста на странице, если она выделена тегами
<noindex>Секретный текст, который не должен попасть в выдачу Яндекса</noindex>
Способ полезный, но ограничен только российским поисковиком — Google эту инструкцию проигнорирует.
Запретите переход по ссылкам
Чтобы надежнее защитить страницу, заблокированную через robots.txt, можно запретить роботам переходить по ссылкам на нее, расположенным на вашем сайте. Для этого можно использовать атрибут rel="nofollow", который нужно будет указать для каждой ссылки:
<a href="ссылка" rel="nofollow">текст</a>
Также запрет переходить по ссылкам можно назначить для страницы целиком. Для этого используйте атрибут “nofollow” в метатеге Robots:
<meta name="robots" content="nofollow">
Здесь тоже не без минусов — запретить переход по ссылкам получится только на страницах, к которым у вас есть доступ. Если на закрытую от сканирования страницу ссылается сторонний сайт, остается шанс, что она окажется проиндексирована.
Установите HTTP-статус
Чтобы закрыть страницу, можно установить один из статусов HTTP:
401 Unauthorized — у пользователя нет прав для посещения ресурса;
403 Forbidden — ресурс закрыт, даже если у пользователя есть нужные права;
404 Not Found — запрашиваемый ресурс не найден на сервере.
Эти HTTP-ответы надежно блокируют страницы от сканирования, но одновременно делают их недоступными для просмотра обычными пользователями — учитывайте это при настройке.
Удалите страницу
Иногда мы не хотим сканировать страницу из-за того, что она утратила актуальность: офисы закрываются, контакты меняются, товары заканчиваются.
Взвесьте все за и против — полезнее ли будет пытаться спрятать устаревшую информацию из выдачи или проще избавиться от нее целиком. Возможно, удаление страницы сократит количество затрат и сэкономит усилия вебмастера.
Закройте страницу паролем
Если блокировка или удаление — не вариант, воспользуйтесь другим способом ограничения доступа к сайту или его отдельным страницам. Вход по паролю — обычное дело для личных кабинетов и других частей сайта, в которых хранятся чувствительные данные.
Также пароль пригодится для тестовой версии сайта. Домен с готовящейся версией можно закрыть от посторонних при помощи заглушки с просьбой войти в систему как администратор — это надежно сохранит процесс от чужих глаз.
Подключите свой сайт к нам, чтобы отслеживать позиции и выявлять ошибки с максимальным комфортом. Вы будете получать уведомления обо всех изменениях на вашем сайте в течение суток — еще до того, как проблема станет серьезной.

Улучшите ваш сайт
Воспользуйтесь инструментами для удаления из индекса
Если вы запретили индексацию страницы или вовсе удалили ее с сайта, но она продолжает появляться в результатах поиска, это значит, что поисковики еще не удалили ее из своих индексов. Ускорить этот процесс можно с помощью специальных инструментов от Яндекс и Google.
Яндекс Вебмастер
В Яндексе это можно сделать с помощью Вебмастера:
Откройте страницу инструмента.
Введите ссылку в поле.
Нажмите Удалить.
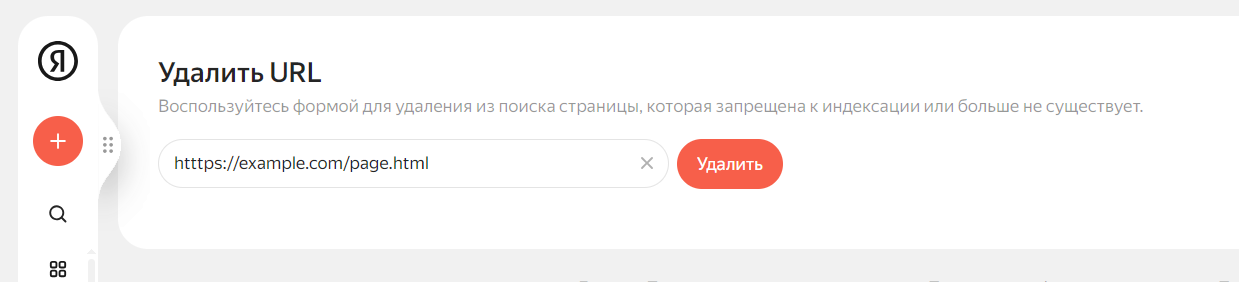
После отправки запроса Вебмастер покажет статус заявки: «В очереди», «В процессе», «Удалена». Если робот выяснит, что страница все еще доступна, он откажется удалять ее из выдачи и отклонит заявку. Прежде чем использовать этот инструмент, закройте тот же URL в robots.txt или убедитесь, что она возвращает один из кодов 401, 403 или 404.
Google Search Console
В Google существует похожий инструмент удаления URL.
Откройте инструмент.
Перейдите на вкладку Временные удаления.
Нажмите Создать запрос.
- Выберите один из вариантов:
Временное удаление URL. Влияет на ссылку целиком и приводит к исключению страницы.
Удаление фрагмента страницы в поиске. Заставляет просканировать страницу заново, чтобы заменить описание в сниппете.
Нажмите Далее и подтвердите отправку запроса.
Search Console также показывает статус запроса в процессе обработки и тоже может отклонить заявку, предоставив подробный отчет о своем решении.
Google называет удаление временным, потому что оно действует всего 6 месяцев — после этого срока страница возвращается в выдачу. Чтобы удалить информацию навсегда, воспользуйтесь одним из указанных выше методов — запретите сканирование страницы, закройте ее от посещений или удалите.
Итоги
На эффективность индексации влияет не только то, оптимизированы ли все нужные страницы, но и то, надежно ли спрятаны все ненужные. Robots.txt — один из способов повлиять на поведение поисковых роботов на вашем сайте и запретить сканирование выбранных страниц, таким образом ускорив обработку действительно важной информации.
Файл дает определенную степень контроля над тем, что попадает в выдачу, но для стопроцентной уверенности мы рекомендуем пользоваться не только robots.txt, но и другими методами, перечисленными в статье. А также не забывайте следить за актуальными рекомендациями от самих поисковиков.










