
Содержание
Парсинг сайтов — удобная возможность получить информацию для бизнеса и аналитики. Используя парсинг, вы можете:
отслеживать обновления статей, показатели валют, новые продукты, прогноз погоды;
анализировать и запускать маркетинговые исследования, например, отслеживать ценообразование у конкурентов;
извлекать данные с иностранных сайтов и переводить их;
анализировать ключи конкурентов для SEO;
работать с социальными сетями и собирать отзывы клиентов.
Что такое парсинг сайтов
Парсинг сайтов — это автоматическое извлечение информации со страниц. Парсят сайты через программы и скрипты — их называют парсерами. Они сканируют веб-ресурсы, извлекают необходимую информацию и конвертируют в таблицы или базы данных.
Парсинг позволяет автоматизировать рутинные процессы и эффективно обрабатывать огромные объемы данных. Будь то сбор цен для анализа конкурентов, мониторинг новостей или создание собственного каталога товаров.
Как работают парсеры
Парсеры работают по заданным алгоритмам и могут собирать информацию в разных форматах: текст, изображения, таблицы, ссылки. Процесс можно разделить на несколько этапов:
Отправка запроса. Парсер отправляет HTTP-запрос (GET или POST) на нужный сайт. В ответ сервер возвращает HTML-код страницы.
Извлечение. Парсер анализирует структуру кода, находит нужные элементы и извлекает их. Это происходит с помощью регулярных выражений, XPath, CSS-селекторов или библиотек для обработки HTML — BeautifulSoup (Python) или Cheerio (JavaScript).
Обработка. Извлеченные данные могут содержать лишние элементы (теги, пробелы, скрытые символы). Парсер очищает и форматирует их, чтобы получить удобный для работы результат.
Сохранение. После обработки данные сохраняются в файлы (CSV, JSON, XML) или базы данных, откуда их можно извлекать для анализа.
Многие парсеры работают по расписанию — автоматически обновляют информацию. Это полезно для мониторинга цен, новостей или изменений на сайтах.
Подпишитесь на нашу рассылку — раз в неделю будем отправлять на ваш email свежую статью из блога и другие полезные материалы.
💌 Еженедельная рассылка
Законность парсеров в РФ
Сам по себе парсинг — всего лишь инструмент. Правомерность использования парсера зависит от целей и метода сбора данных.
Здесь роль играют несколько законов:
«О персональных данных» (№ 152-ФЗ). Если парсер собирает ФИО, номера телефонов, емейлы, адреса, то обработка такой информации требует согласия владельцев.
«Об информации, информационных технологиях и о защите информации» (№ 149-ФЗ). Доступ к открытой информации на сайте не ограничен, но если владелец ресурса запрещает автоматизированный сбор данных и указывает это в файле robots.txt или в пользовательском соглашении, использовать парсер будет нарушением.
Авторское право (ГК РФ, глава 70). Если парсер копирует и использует контент, который находится под авторским правом, это нарушает закон.
«О коммерческой тайне» (№ 98-ФЗ). Запрещено собирать и распространять данные, которые являются коммерческой тайной: например, внутренние документы компаний или закрытую статистику.
Как парсить сайт законно:
собирать только общедоступные данные;
выполнять условия пользовательского соглашения;
использовать данные в аналитических или исследовательских целях — без нарушения авторских прав.
Типы парсеров по сферам применения
Парсить полезно в любой сфере: от работ по SEO до анализа кейсов и автоматизации бизнес-процессов. В зависимости от целей парсеры могут использоваться для мониторинга цен, сбора отзывов, анализа контента и конкурентов.
SEO
В поисковой оптимизации парсеры используют для анализа сайтов конкурентов, поиска ключевых слов, сбора метаданных и технического аудита страниц.
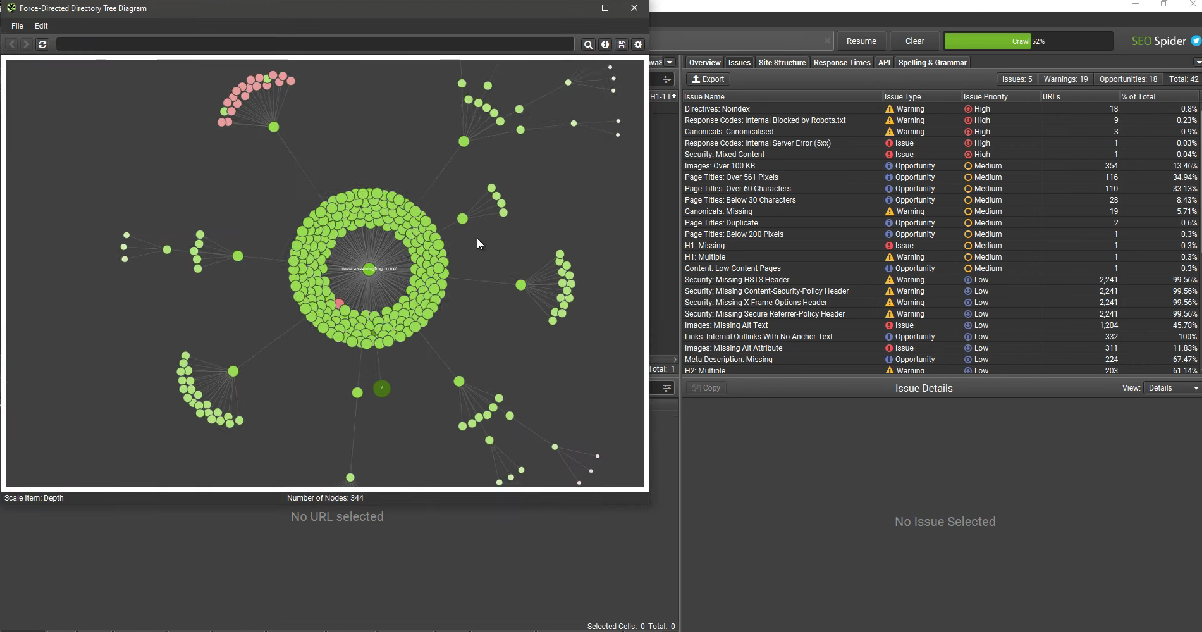
Среди примеров задач — извлечение метатегов (title, description, h1) для анализа семантики, определение структуры URL, выявление проблем с индексацией. Можно настроить мониторинг изменений в поисковой выдаче, поиск битых ссылок и технических ошибок, сбор ключевых слов и анализ их частотности.
Подключите свой сайт к нам, чтобы отслеживать позиции и выявлять ошибки с максимальным комфортом. Вы будете получать уведомления обо всех изменениях на вашем сайте в течение суток — еще до того, как проблема станет серьезной.

Улучшите ваш сайт
Интернет-магазины и e-commerce
Компании в сфере e-commerce стремятся устанавливать конкурентоспособные цены и предлагать покупателям наиболее выгодные условия. Для этого можно парсить цены — автоматически собирать стоимость товаров у конкурентов.
Еще в сфере e-commerce парсить можно, чтобы:
собирать информацию о скидках и акциях;
анализировать карточки товаров — описания, изображения, характеристики;
изучать тренды и отслеживать появление на рынке новых товаров;
извлекать отзывы покупателей, чтобы понимать потребности аудитории и недостатки продукта.
Парсеры для проверки цен работают в несколько шагов:
анализируют магазины и извлекают названия товаров, цены, информацию о скидках, условиях доставки и другие параметры.
обрабатывают и структурируют данные, чтобы специалист мог легко сравнить их с аналогичной информацией по собственной компании.
Большинство парсеров цен поддерживают регулярное обновление данных. Это особенно важно для динамического ценообразования, когда стоимость товаров корректируется в зависимости от спроса, сезонности или действий конкурентов. Например, если конкурент снижает цену на популярный товар, система может автоматически предложить клиентам скидку или бонус, чтобы удержать их.
Парсинг цен имеет свои технические сложности. Многие интернет-магазины используют механизмы защиты: блокировку частых запросов или динамическую подгрузку данных с помощью JavaScript. В таких случаях парсеры обходят ограничения через прокси-серверы или имитируют поведение реальных пользователей.
Организация совместных покупок
Совместные покупки (СП) — это способ приобрести товары по оптовым ценам, объединяя заказы нескольких покупателей. Организаторы СП используют парсеры, чтобы автоматизировать работу с поставщиками и оптимизировать оформление заказов.
Основная задача парсеров для СП — сбор данных о товарах с сайтов поставщиков. Это позволяет быстро обновлять ассортимент и избегать ручного ввода данных. Среди прочих задач:
анализ цен и условий доставки;
мониторинг остатков товаров;
отслеживание акционных предложений и их интеграция в каталог СП.
Контент-маркетинг
Контент-маркетологи парсят, чтобы анализировать успешные материалы, собирать идеи для статей и исследовать конкурентов.
Парсеры способны анализировать заголовки и структуру популярных статей, собирать комментарии и пользовательские вопросы. Еще можно настроить мониторинг новых публикаций на тематических сайтах. На всей этой основе авторы создают полезный контент.
Сбор данных из социальных сетей
Социальные сети — огромный источник информации о трендах, реакциях аудитории и предпочтениях пользователей.
Примеры задач в этой сфере:
сбор постов и комментариев по ключевым словам или хэштегам;
мониторинг активности конкурентов;
анализ отзывов и оценок пользователей.
Аналитика и маркетинговые исследования
Аналитики и маркетологи используют парсинг для мониторинга рынка, исследования потребительского спроса и конкурентного анализа:
изучают отзывы клиентов, чтобы выяснить их боли и потребности;
собирают информацию о новых продуктах и услугах;
мониторят тренды на отраслевых сайтах и форумах.
Типы парсеров по их решению
Все парсеры можно разделить на облачные и десктопные решения:
Облачные парсеры работают на удаленных серверах и поэтому не требуют локальной установки. Они подходят для обработки крупных объемов данных.
Десктопные парсеры устанавливаются непосредственно на компьютер пользователя. Они позволяют гибко настраивать параметры работы и дают больше контроля над процессом.
Выбор решения зависит от ваших задач: для больших объемов данных лучше парсить на облаке, для разовых задач — использовать десктопные версии.
Облачные
Облачные парсеры не занимают ресурсы пользователя и могут работать круглосуточно без участия человека. Как они работают:
Пользователь указывает сайт и элементы, которые необходимо извлечь: текст, изображения, цены, отзывы и т.д. У большинства сервисов есть графический интерфейс, который позволяет легко выбирать нужные данные из списка.
Парсер отправляет запросы к веб-страницам, считывает HTML-код или загружает страницу полностью, если используется JavaScript-рендеринг.
Программа извлекает нужную информацию по заданным параметрам.
Парсер очищает информацию от лишнего кода и преобразует в удобный для пользователя формат (CSV, JSON, Excel, API). В некоторых случаях инструмент обрабатывает данные с помощью ИИ: например, распознает текст на изображениях.
Полученные данные можно скачать, отправить в базу данных, передать в CRM или проанализировать в Google Таблицах и Excel.
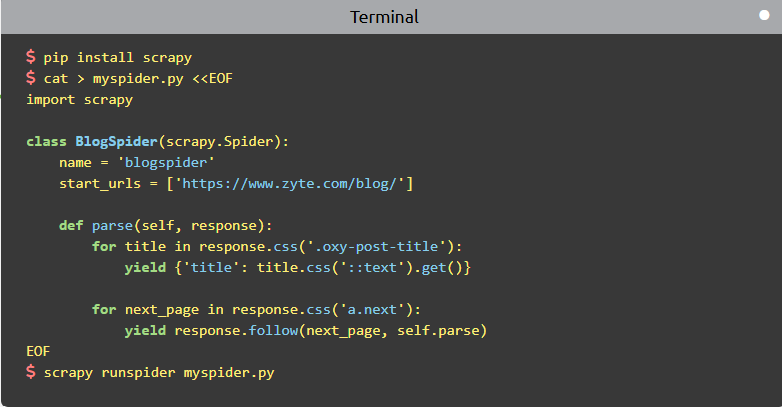
Преимущества облачных парсеров:
работают 24/7 и могут выполнять задачи постоянно, даже если компьютер выключен;
не нагружают локальные ресурсы — обработка данных происходит на сервере, а не на устройстве пользователя;
не требуют навыков программирования;
при необходимости интегрируются с другими сервисами.
Недостатки облачных парсеров:
необходимость оплачивать тарифы;
есть ограничения на сложные задачи;
некоторые сайты защищены от парсинга, и облачные сервисы не справляются без дополнительных настроек;
работа зависит от стабильного интернет-соединения.
Десктопные
Десктопные парсеры работают локально — используют вычислительные ресурсы пользователя. Они могут решать задачи разными способами:
анализировать HTML-код страниц и извлекать нужные данные на основе заранее заданных шаблонов;
загружать сайты через эмулятор поведения реального пользователя — это полезно в работе с динамическими страницами, где контент подгружается с помощью JavaScript;
поддерживать автоматизацию действий: переходы по ссылкам, ввод данных в формы и работу с CAPTCHA.
Преимущества десктопных парсеров:
большая гибкость в настройке парсинга: пользователь может выбирать параметры работы программы, задавать сложные алгоритмы обработки данных, интегрировать парсер с другими инструментами;
обход ограничений, которые сайты устанавливают против автоматизированного сбора информации;
полный контроль за процессом парсинга.
Недостатки десктопных парсеров:
у многих десктопных решений сложный интерфейс;
потребуются навыки программирования или хотя бы базовое понимание принципов работы веб-страниц;
компьютер должен быть включен на протяжении всего процесса сбора данных: это неудобно, если парсинг должен работать регулярно без участия пользователя.
Типы парсеров по технологии работы
Тип парсера | Особенность | Преимущества | Недостатки | Примеры инструментов |
HTML-парсеры | Используют регулярные выражения, XPath или CSS-селекторы для извлечения данных из HTML-кода страницы. | Простая реализация, высокая скорость работы. | Ломаются при изменении структуры сайта. | BeautifulSoup, lxml |
API-парсеры | Получают данные через официальные API сайтов. | Надежны, легальны, не зависят от изменений структуры сайта. | Ограничения API (лимиты запросов, доступность данных). | Requests, Postman |
JavaScript-парсеры | Используют браузерные движки для работы с динамическими сайтами, где контент загружается с помощью JavaScript. | Поддержка динамических страниц и сложных сценариев. | Медленная работа, высокая потребность в ресурсах. | Selenium, Puppeteer |
Парсеры с машинным обучением | Применяют нейросети для обработки сложных данных. | Извлечение данных из изображений, PDF, плохо структурированных страниц. | Сложность разработки, высокая вычислительная мощность. | Tesseract, Google Vision API |
Гибридные парсеры | Комбинируют несколько технологий (например, рендеринг + HTML). | Высокая гибкость и возможность обхода сложных структур. | Усложнение архитектуры и настройки. | Scrapy с Selenium, Playwright |
Инструменты для SEO-парсинга
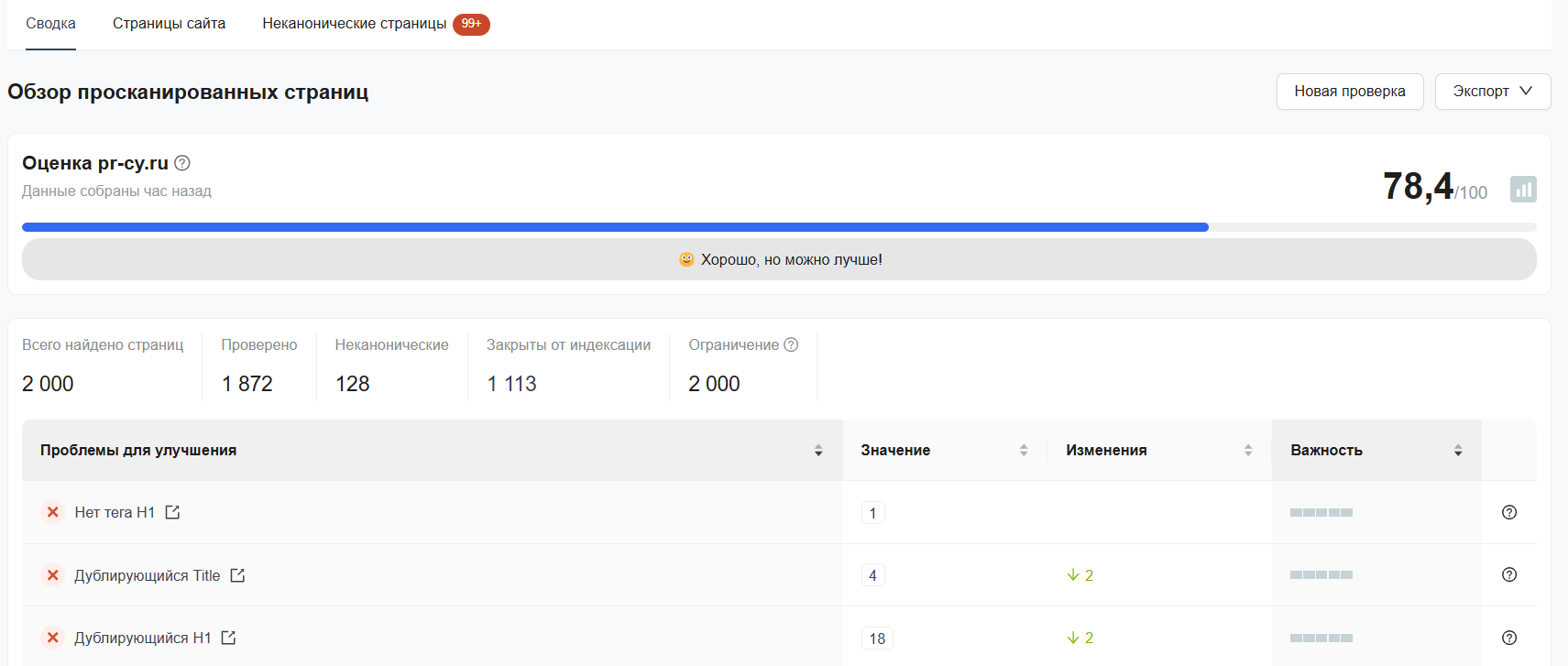
Аудит сайта PR-CY — автоматически проверяет ресурс на технические проблемы, которые влияют на SEO. Инструмент анализирует скорость загрузки страниц, корректность редиректов, ошибки 404, дубли метатегов, правильность заголовков H1 и другие параметры. После анализа сервис выдает сводный отчет со списком тестов, общей оценкой сайта и цветовой маркировкой ошибок.
Screaming Frog SEO Spider — одно из самых мощных решений для детального анализа сайта. Позволяет сканировать веб-страницы, исследовать метаданные, выявлять неработающие ссылки и другие технические ошибки. Отлично подходит, чтобы проверить структуру сайта, найти битые ссылки и проанализировать показатели загрузки страниц.
Netpeak Spider — аналог Screaming Frog с более понятным интерфейсом и дополнительными функциями для SEO. Эффективен для анализа внутренней связности сайта, поиска дубликатов страниц и проверки корректности редиректов.
Serpstat Scraper — инструмент для извлечения данных из поисковой выдачи (SERP), анализа ключевых запросов и отслеживания позиций сайта.
Xenu's Link Sleuth — бесплатная программа для поиска неработающих ссылок и оценки доступности веб-страниц.
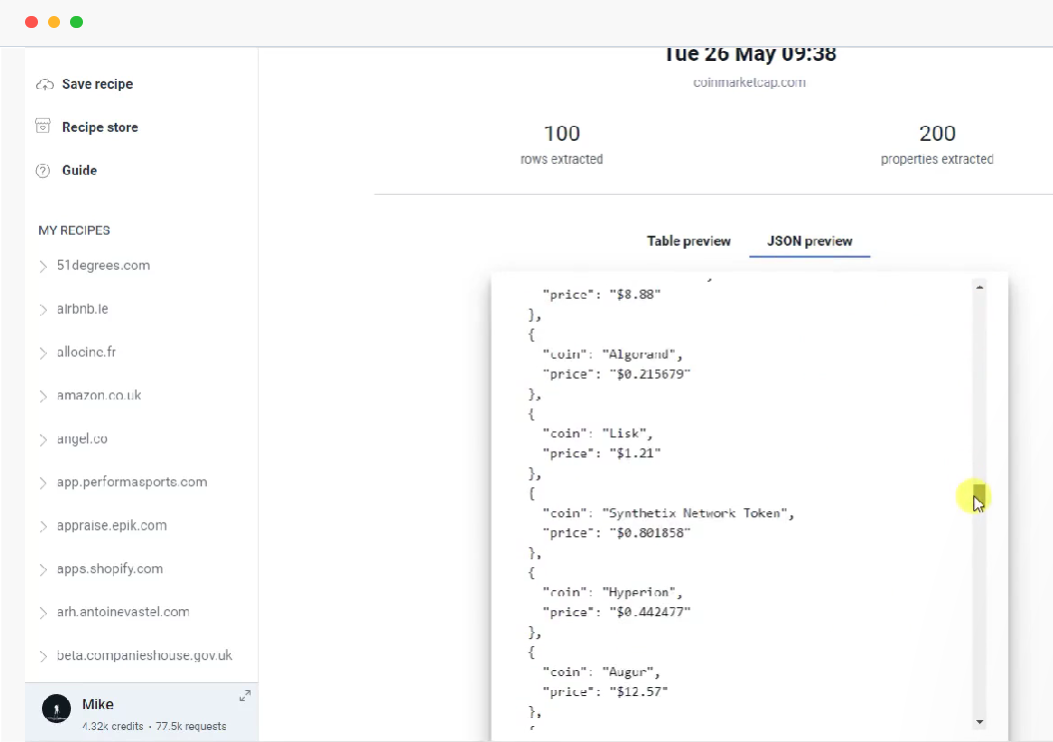
Scrapy (Python) — универсальная библиотека для создания кастомных парсеров. Подходит для сложных задач в сфере SEO: например, для анализа конкурентного контента и автоматического сбора данных для исследований.
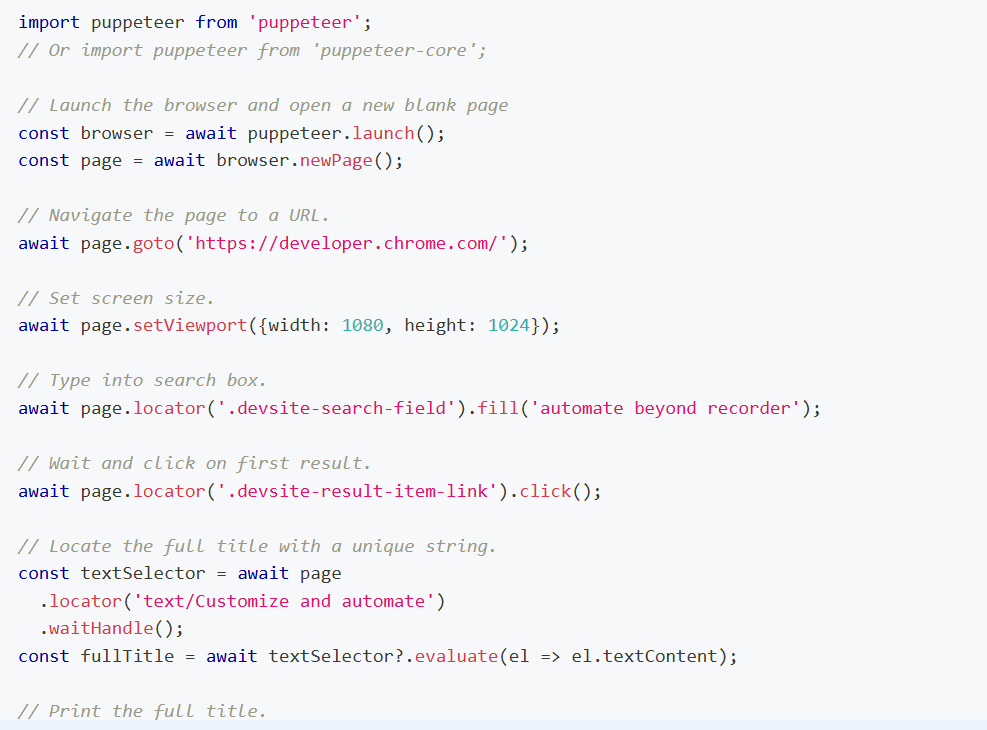
Puppeteer — мощный инструмент для работы с динамическими страницами, которые грузят контент через JavaScript. Эффективен для анализа SPA-сайтов и контента с использованием AJAX.
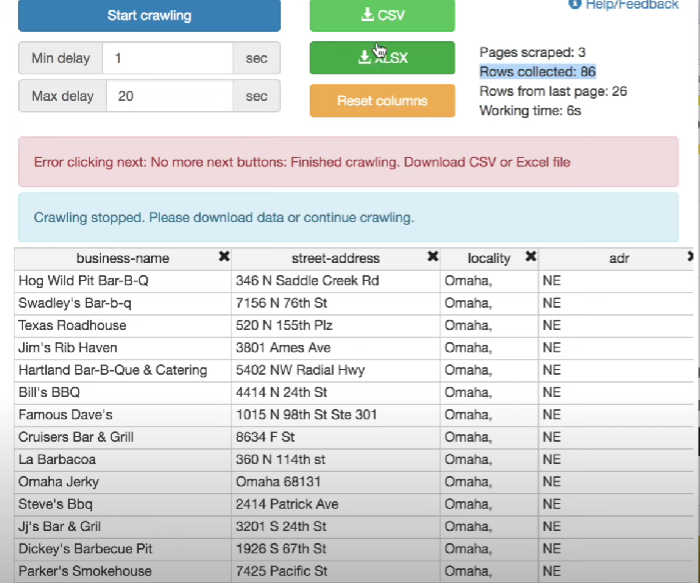
Расширения для SEO-парсинга в Google Chrome
Data Scraper — Easy Web Scraping. Позволяет извлекать данные из таблиц, списков и других элементов без программирования.
Instant Data Scraper. Полуавтоматический инструмент, который автоматически распознает таблицы и списки на веб-страницах.
Simple Scraper. Минималистичный инструмент для сбора данных с сайтов, удобный для быстрого копирования контента.
Link Klipper — Extract all links. Расширение для быстрого сбора всех ссылок со страницы.
SEO Minion. Позволяет анализировать страницы и собирать важные данные — метатеги, заголовки, внутренние и внешние ссылки.
Методы защиты сайтов от парсинга и как их обойти
Иногда ресурсы пытаются ограничить парсинг, чтобы защитить информацию. Для этого используют разные методы: от ввода капчи до блокировки.
CAPTCHA
Это один из самых распространенных способов защиты. Пользователю предлагают выполнить задание, которое сложно решить боту. Например, выбрать изображения, разгадать текст или отметить галочкой «Я не робот».
Как обойти:
Если парсинг выполняется в небольших масштабах, можно вводить CAPTCHA вручную.
Есть специальные API-сервисы — 2Captcha, Anti-Captcha, DeathByCaptcha. Они автоматически распознают и решают капчи. Их мы подробно разбирали в этой статье.
Некоторые CAPTCHA активируются только при аномальной активности. Поэтому если замедлить парсинг, делать паузы между запросами и эмулировать движение мыши, можно избежать проверки.
Иногда капчи активируются только при использовании определенных IP-адресов или браузеров. Поможет изменение этих параметров.
Ограничение скорости запросов (Rate Limiting)
Сайты отслеживают количество запросов с одного IP-адреса за короткий промежуток времени. Если лимит превышен, сервер временно блокирует доступ или требует решить капчу.
Как обойти:
Снизить частоту обращений к сайту, чтобы не превышать установленные лимиты.
С помощью прокси-серверов или VPN менять IP-адрес, чтобы сервер не распознавал активность как подозрительную.
Распределять запросы через несколько машин (Distributed Crawling).
Использовать реальные заголовки User-Agent.
Блокировка IP-адреса
Иногда сайты настраивают блокировку IP-адресов, если ресурс обнаруживает, что с одного адреса поступает слишком много запросов.
Как обойти:
Использовать прокси.
Подключаться через браузер TOR.
Использовать облачные сервисы с динамическими IP-адресами.
Клоакинг (Cloaking)
Разным пользователям сайт показывает разный контент. Например, если запрос приходит от поискового робота Google, сайт выдает одну информацию, а если запрос от обычного пользователя — другую.
Сервисы могут анализировать IP, User-Agent и поведение пользователя, чтобы определить, кто именно делает запрос.
Как обойти:
Использовать заголовки реального браузера (User-Agent, Referer, Cookies).
Использовать прокси.
Парсить через специальные браузеры, которые эмулируют работу настоящего пользователя.
Запросить кэшированную версию страницы через Google или Яндекс.
Несколько советов по обходу блокировок
Используйте прокси-серверы: они помогают обходить блокировки, маскировать IP-адреса и распределять нагрузку между источниками запросов. Это полезно в работе с сайтами, которые ограничивают частоту обращений с одного IP.
Всегда учитывайте нагрузку на сервер: слишком частые запросы приведут к блокировке или замедлят работу ресурса. Чтобы избежать проблем, стоит настроить задержки между запросами и использовать ротации IP и распределенный парсинг.
Чек-лист: как выбрать подходящий парсер
Шаг | Что нужно учесть |
1. Определите цели и задачи парсера. | - Какие данные нужно извлекать? - Сколько раз и в какой промежуток нужно обновлять информацию (ежедневно, еженедельно, в реальном времени)? - Нужна ли обработка сложных структур или динамического контента? |
2. Оцените структуру сайта. | - Сайт статический или динамический? - Есть CAPTCHA, блокировка IP и другая защита от парсинга? - Сайт поддерживает API, чтобы получать данные? |
3. Выберите технологию парсинга. | - HTML-парсер: для простых сайтов без динамического контента. - API-парсер: если сайт предоставляет удобный API. - Парсер на основе рендеринга: для динамических сайтов. - Гибридные решения: для сложных задач. |
4. Оцените объем и частоту данных. | - Какой объем данных нужно обрабатывать за один запуск? - Нужен ли многопотоковый режим работы? - Требуется ли хранение данных в базе данных (PostgreSQL, MongoDB)? |
5. Проверьте требования к авторизации. | - Требуется ли вход в личный кабинет? - Нужна ли поддержка работы с сессиями и cookies? |
6. Оцените инструменты и библиотеки. | - Простота интеграции и настройки. - Поддержка сообщества и документация. - Совместимость с языком программирования вашего проекта (Python, Node.js). |
7. Проверьте производительность. | - Время работы парсера. - Возможность работы в параллельных потоках. - Оптимизация запросов к сайту. |
8. Учитывайте легальность. | - Есть ли разрешение на парсинг данных? - Не нарушается ли политика конфиденциальности сайта? |
9. Рассмотрите готовые решения. | - Поддерживает ли парсер интеграцию с CRM или Google Таблицами? - Есть ли платные SaaS-сервисы, которые могут полностью закрыть вашу задачу? |
10. Протестируйте парсер перед внедрением. | - Корректно ли извлекаются все нужные данные? - Парсер справляется с изменениями структуры сайта? - Как быстро он выполняет задачи? |
FAQ
Как не попасть под блокировку?
Меняйте IP-адреса через прокси-серверы и настройте паузы между запросами, чтобы имитировать поведение реального пользователя.
Учитывайте robots.txt, если сайт его предоставляет.
Работайте через динамический рендеринг с использованием браузеров.
Как протестировать работу парсера?
Для начала проверьте корректность извлечения всех нужных данных. Затем убедитесь, что парсер устойчив к изменениям структуры сайта. И оцените скорость выполнения задач.
Можно ли парсить сайты через мобильное подключение? Зачем это делать?
Да, можно. Использование мобильных сетей полезно, когда требуется избежать блокировок со стороны сайта. Мобильные сети часто предоставляют динамические IP-адреса, которые сложно отследить и заблокировать.
Это особенно актуально, если основной интернет-провайдер уже попал под блокировку сайта. Рекомендуем использовать USB-модемы или мобильные точки доступа в связке с прокси-настройками для стабильности работы.
Какие данные лучше не парсить, чтобы избежать юридических проблем?
Чтобы избежать правовых рисков, избегайте парсинга следующих данных:
ФИО, контактные номера, емейлы без разрешения владельцев;
закрытая информация, которая требует авторизации или защищена паролями;
контент, защищенный авторским правом — полные копии статей, изображений, видео или других материалов;
данные, составляющие коммерческую тайну — закрытые статистики, внутренние документы компаний.
Чем плох многопотоковый парсинг и когда его стоит избегать?
Многопотоковый парсинг позволяет отправлять множество запросов одновременно — это увеличивает скорость извлечения данных. Но сайты могут посчитать такую активность подозрительной и заблокировать ваш IP. Еще если сервер сайта слабый, многопоточные запросы могут создать дополнительную нагрузку.
Как автоматизировать парсинг с минимальными усилиями?
Если вы не хотите постоянно запускать парсер вручную, настройте cron-задачи на сервере для регулярного запуска парсинга. Используйте облачные сервисы с поддержкой расписаний (например, ParseHub или Apify) и автоматизируйте выгрузку данных через интеграции с Google Таблицами или CRM.
Можно ли использовать результаты парсинга для коммерческих целей?
Да, но с оговорками:
если данные общедоступны и не защищены авторским правом;
если они получены без нарушения пользовательского соглашения сайта.






