
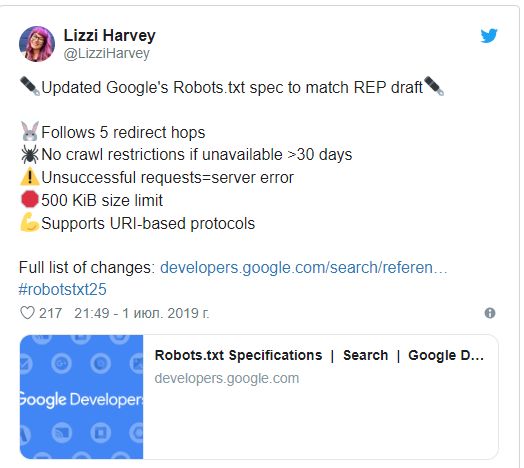
Главные изменения выглядят так:
- файл robots.txt стал поддерживать все URI-протоколы;
- Google отказался от раздела «Язык требований»;
- для переадресации Гуглбот использует как минимум пять повторений. В случае необнаружения файла robots.txt цикл обращений завершается и присваивается код ошибки 404;
- неполные данные и неудачные запросы расцениваются поисковиком как ошибка на стороне сервера;
- в случае отсутствия доступа к robots.txt свыше 30 дней (ошибки 5xx) Google будет использовать последнюю сохраненную в кэше копию файла. Если и к ней доступа нет, это сигнал, что сканировать можно все страницы;
- поисковая система отказывается распознавать элементы файла с опечатками и/или ошибками (к примеру, «useragent» вместо «user-agent»);
- максимальный размер файла robots.txt, который способен обработать Google, 500 кибибайт (КиБ).
В обновленной документации Google по robots.txt
также исчезли отсылки к более неактуальной схеме сканирования Ajax. Кроме того, обновлен формальный синтаксис (добавлены символы UTF-8) и определение «групп» (появился пример пустой группы).






