
В кругу сеошников бытует мнение, что чем больше запретов на индексацию страниц сайта прописано в файле Robots.txt, тем реже в итоге поисковый робот посещает такой ресурс. То есть, так называемый «краулинговый бюджет» сайта уменьшается в размерах.
Так ли это на самом деле, попытался выяснить один веб-мастер:
«URl-адреса, которые я запрещаю индексировать в Robots.txt, каким-то образом влияют на совокупный краулинговый бюджет сайта?»
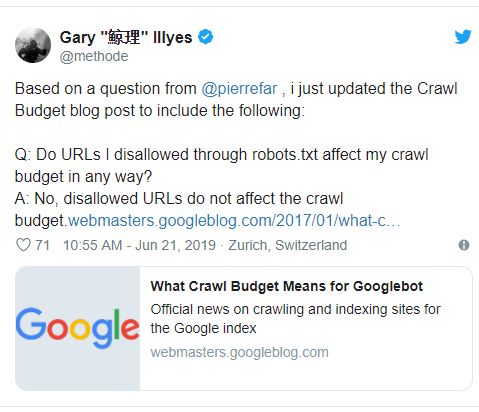
От имени Google однозначно ответил Гари Илш:
«Нет, запрещенные урлы никоим образом не влияют на такого рода бюджет».
Иначе говоря, блокировать индексацию «ненужных» страниц в файле Robots.txt можно смело. Посещать вас реже при этом гуглбот не станет.
Напомним, недавно мы рассказывали, как составить Robots.txt самостоятельно.






