
Краткое саммари
cURL — это встроенная программа командной строки, которая позволяет отправлять HTTP-запросы к серверам и получать ответы. Для SEO-специалистов cURL незаменим для проверки того, как поисковые боты видят страницы сайта, отслеживания редиректов, проверки HTTP-заголовков и работы с закрытыми страницами под авторизацией.
В статье вы узнаете, как использовать cURL для технического аудита сайта, как притвориться поисковым ботом (Googlebot, Yandexbot, AI-краулерами), как проверить цепочки редиректов и какие обновления произошли в инструменте за 2024-2026 годы.
Кому стоит прочитать эту статью:
- SEO-специалистам — для технического аудита сайтов и проверки индексации
- Вебмастерам — для диагностики проблем с редиректами и HTTP-заголовками
- Маркетологам — для понимания, как поисковики видят контент сайта
- Разработчикам — для работы с API и тестирования серверных ответов
Содержание
Статью подготовил Юрий Никулин, эксперт в продуктовом SEO. Юрий — преподаватель в it-школах «Нетология» и «CyberMarketing», победитель Сколково в номинации «Лучший стартрап в сфере IT технологий» в 2023 году и модератор на конференции «Optimization». Статья обновлена в 2026 году с актуальной информацией о cURL и SEO-трендах.
Что такое cURL и зачем он нужен для технического SEO-аудита
cURL (Client URL) — это встроенная программа командной строки, которая позволяет отправлять HTTP-запросы к серверам и получать ответы. Она доступна по умолчанию в Windows 10+, macOS и Linux, что делает её универсальным инструментом для технического SEO-аудита.
По состоянию на 2026 год, последняя версия cURL — 8.18.0 (выпущена в январе 2026), которая включает улучшения безопасности и поддержку современных протоколов. Для SEO-специалистов в 99% случаев нужны только HTTP и HTTPS:
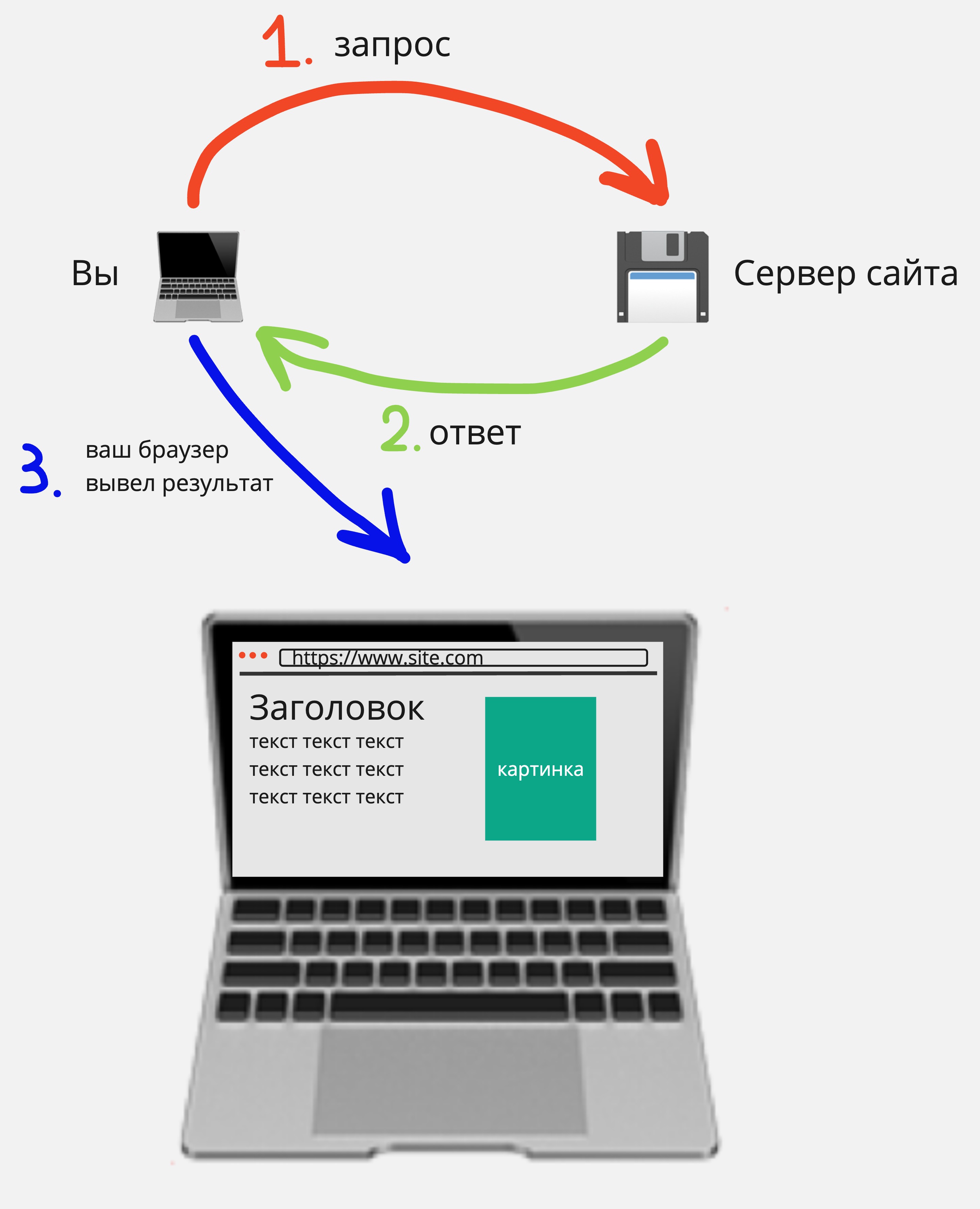
HTTP — устаревший незащищенный протокол передачи данных между вашим компьютером (браузером) и сервером сайта. Пример: http://www.site.com. В 2026 году Google и Яндекс рекомендуют полностью переходить на HTTPS.
HTTPS — расширение протокола HTTP с шифрованием данных. Пример: https://www.site.com. Это стандарт безопасности для всех современных сайтов и обязательное требование для хороших позиций в поисковой выдаче.
Так выглядит простейшая схема работы протокола HTTP/HTTPS:
FAQ: Что такое cURL
В чем разница между cURL и браузером для SEO-проверок?
Браузер выполняет JavaScript, рендерит страницу и может скрывать часть контента. cURL показывает "сырой" HTML-код, который получает сервер — именно это видит поисковый бот при первой индексации. Это позволяет точно определить, какой контент доступен для индексации.
Нужно ли устанавливать cURL отдельно?
В большинстве случаев нет. cURL встроен в Windows 10+, macOS и Linux. Если у вас старая версия Windows (до 10), скачайте cURL с официального сайта curl.se. Проверить наличие можно командой curl --version в терминале.
Как установить и проверить cURL: инструкция для Windows, macOS и Linux
Рассмотрим, как работать с cURL на разных операционных системах.
Windows
Для Windows 10 и новее cURL установлен по умолчанию. Если у вас более старая система, скачайте cURL с официального сайта.
Нажмите «Пуск» и введите поиске фразу «Windows terminal». Далее начинайте вводить запросы cURL. Самый распространенный по типу “Hello World” — curl --version, он позволяет проверить версию.
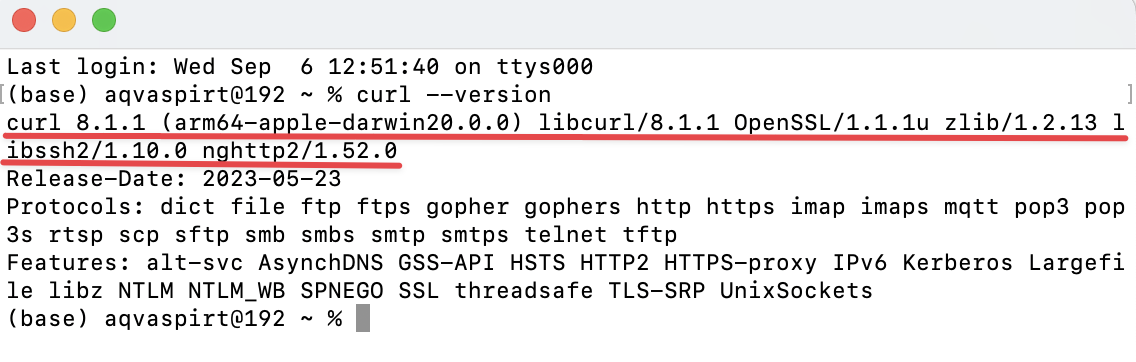
MacOS
Откройте “Launcher” и через поиск выберите там “Terminal”. Введите аналогичный запрос curl --version, после этого должна появиться версия curl, например, вот так:
Linux
На Linux cURL тоже установлен по умолчанию. Для проверки версии cURL на Linux введите в терминале curl --version.
FAQ: Установка и проверка cURL
Как узнать, какая версия cURL установлена на моем компьютере?
Откройте терминал (Windows Terminal, Terminal на macOS/Linux) и введите команду curl --version. Вы увидите версию cURL и список поддерживаемых протоколов. Для SEO-задач подойдет любая версия начиная с 7.0, но рекомендуется использовать версию 8.0 и выше для поддержки современных функций безопасности.
Что делать, если команда curl не найдена в Windows?
Если вы используете Windows 7 или 8, скачайте cURL с официального сайта curl.se/windows. Для Windows 10 и 11 cURL должен работать из коробки. Если не работает, обновите Windows или установите последнюю версию cURL вручную.
Главная особенность cURL для SEO: как проверить, что видит поисковый бот
cURL позволяет узнать, как поисковые боты индексируют и видят страницу. Если хотите понять, какой текст HTML скрыт от глаз поисковиков или какие HTTP-заголовки ответа сервера получают боты, cURL поможет. Это критически важно для технического SEO-аудита в 2026 году, когда поисковики стали еще строже относиться к контенту, доступному для индексации.
На что он способен:
Заменять user-agent — притвориться Googlebot, Yandexbot или AI-краулерами (GPTBot, ClaudeBot, PerplexityBot);
Проходить базовую аутентификацию — проверять закрытые страницы глазами поисковиков;
Получать HTTP-заголовки и отслеживать цепочки редиректов — находить проблемы с редиректами, которые могут влиять на индексацию;
Получать HTML страницы — видеть "сырой" код, который получает поисковый бот при первой индексации.
Три причины, почему это лучше, чем браузер и его расширения:
Чтобы контролировать процесс самому, в cURL баги не допустимы;
Чтобы притвориться поисковиком, такое может браузер и некоторые расширения;
Расширения в Google Chrome не могут менять user-agent. Только те, которые строятся на платформенных решениях и выносятся на отдельный сервер.
Пройдемся по каждой из особенностей, опишем возможные задачи и их решения. Особое внимание уделим новым AI-краулерам, которые стали активно индексировать контент в 2024-2026 годах.
Замена user-agent: как проверить страницу глазами Googlebot, Yandexbot и AI-краулеров
Задача
Вы хотите посмотреть страницу глазами Яндекса, Google или AI-краулеров (GPTBot, ClaudeBot, PerplexityBot) и увидеть, какой контент им недоступен. У них, конечно, есть свои инструменты, но Яндекс ограничивает отдачу HTML через инструмент «Проверка ответа сервера» в 50 000 строк, а «Google mobile-friendly test» перестал работать для сторонних сайтов. Кроме того, в 2024-2026 годах появились новые AI-краулеры, которые индексируют контент для обучения нейросетей — важно проверить, что они видят на вашем сайте.
Решение
Шаг 1: вводим команду
Откройте терминал и введите следующую команду: curl -A "user-agent" URL. Из чего состоит команда:
- -A — эта опция используется для установки user-agent в HTTP запросе к серверу сайта. К примеру мы хотим притвориться Google. По другому, мы говорим: “Эй, сервер, мы поисковый бот Google! Дай нам тот контент, который ты хочешь показывать этому поисковику”;
- “user -agent” — вставляем от поискового бота, в нашем случае от Google:
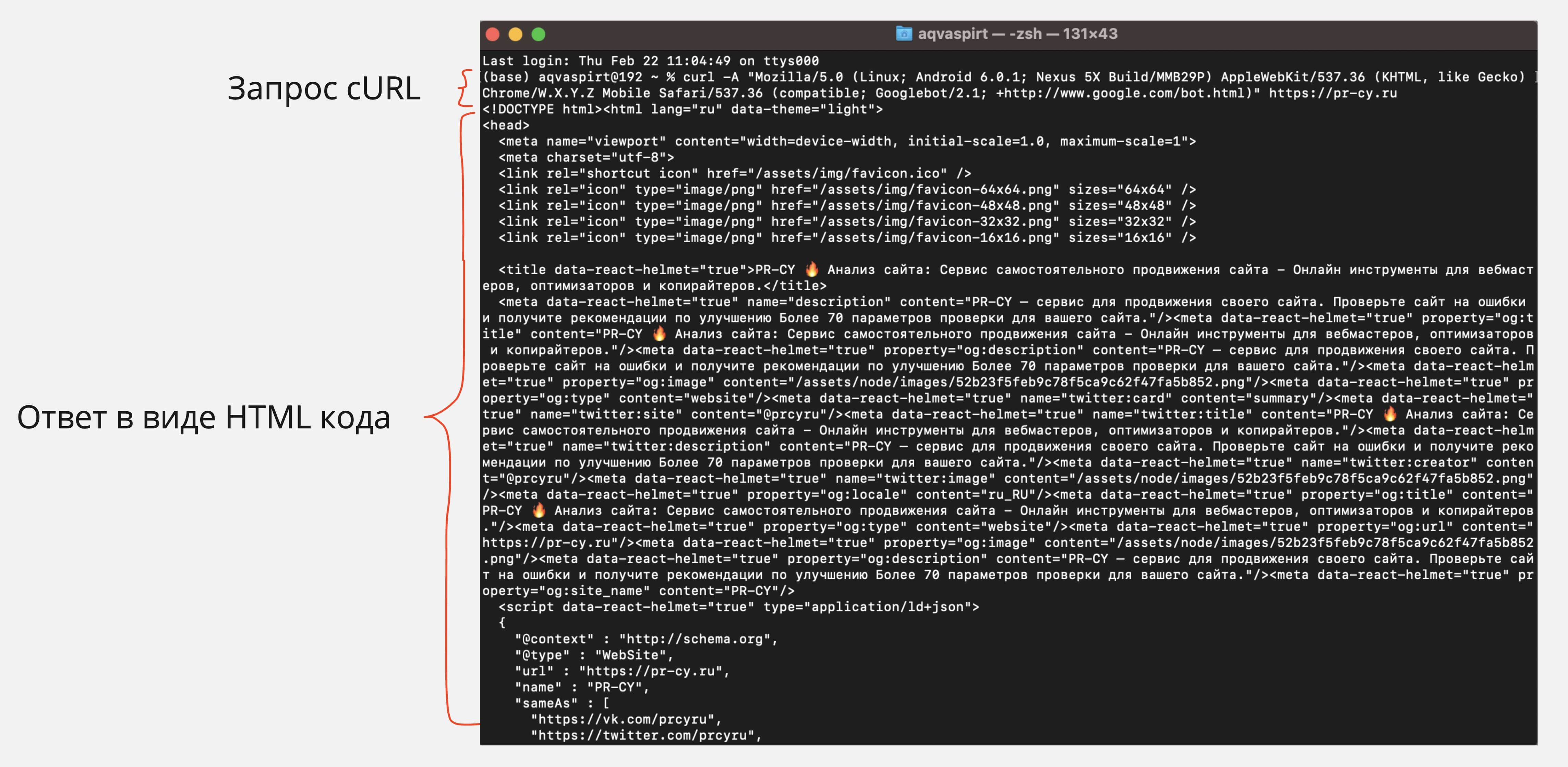
curl -A "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://pr-cy.ru
Важно: С 2019 года Googlebot использует "evergreen" версию Chrome, которая постоянно обновляется. User-agent Googlebot теперь всегда содержит актуальную версию Chrome (формат W.X.Y.Z). Googlebot Smartphone стал основным краулером для mobile-first индексации даже для десктопных результатов.
Список актуальных user-agent Google можно посмотреть в официальной документации. От Яндекса документация представлена в таблице в разделе «Основные поисковые роботы».
AI-краулеры (2024-2026): В последние годы появились новые краулеры для обучения AI-моделей. Вы можете проверить, что они видят на вашем сайте:
GPTBot (OpenAI):
curl -A "GPTBot" https://your-site.comClaudeBot (Anthropic):
curl -A "anthropic-ai" https://your-site.comPerplexityBot:
curl -A "PerplexityBot" https://your-site.com
Трафик AI-краулеров вырос на 6900% с 2024 по 2026 год, поэтому важно контролировать, какой контент они индексируют. Вы можете разрешить или запретить их доступ через robots.txt.
В итоге cURL возвращает следующий ответ:
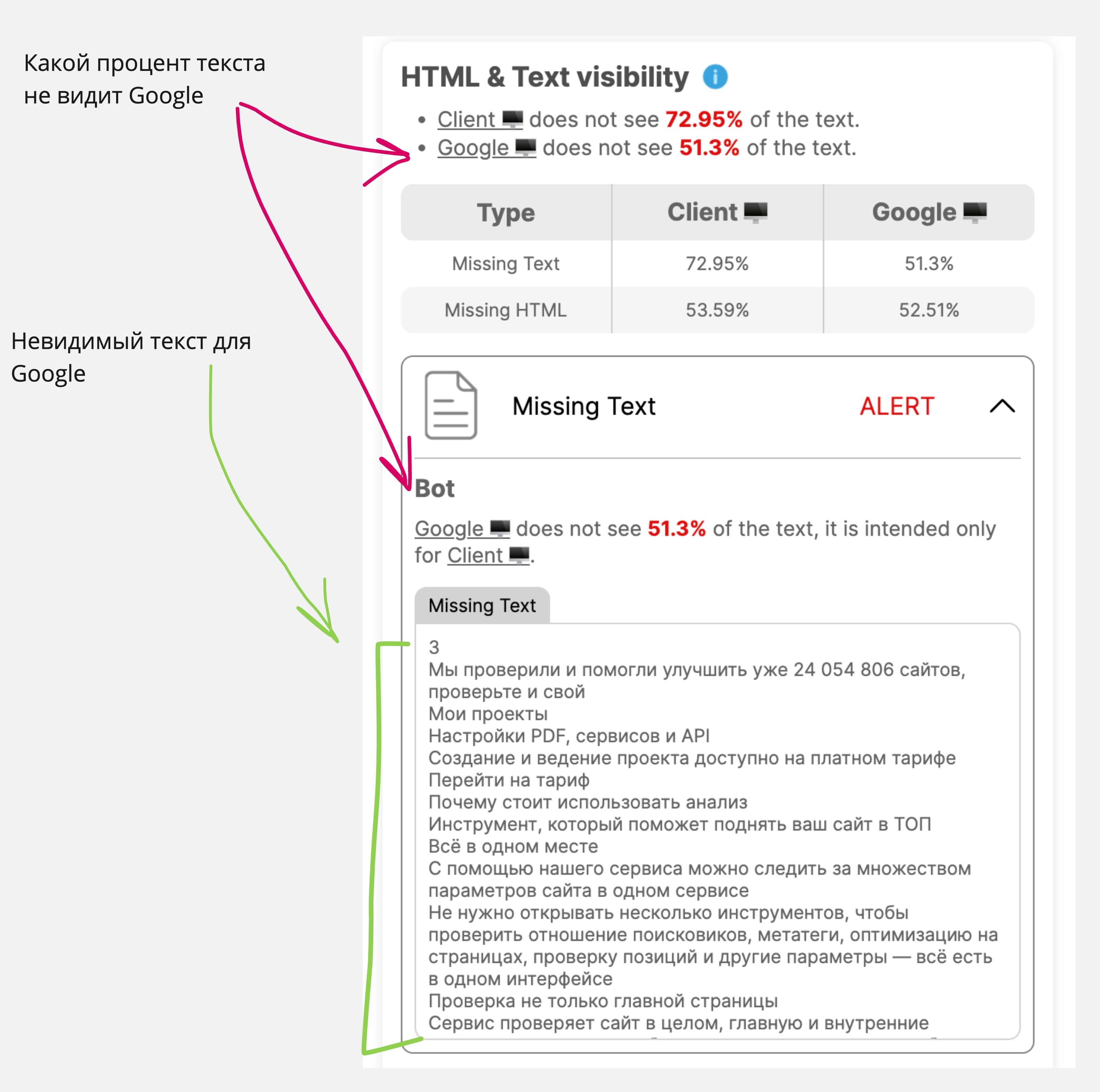
Шаг 2: ищем невидимый для Google контент
Есть четыре пути определения контента, который не видит поисковый бот:
1. Очистите текст, который вам выдал cURL, от HTML-тегов, либо найдите любой онлайн-сервис по запросу «Очистить текст от HTML тегов», либо в DevTools в разделе Console введите javascript код console.log(document.body.textContent); и скопируйте полученный текст в какой-нибудь редактор.

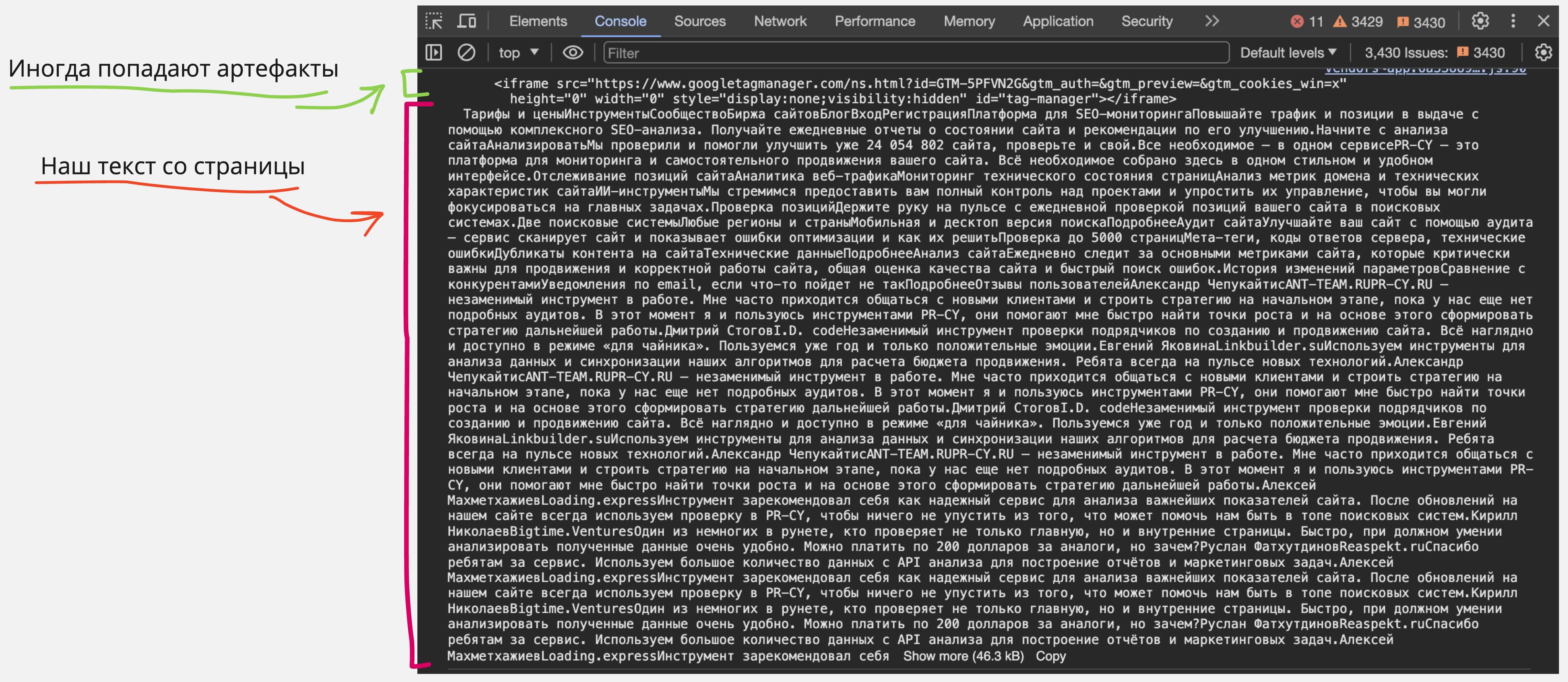
Сравните тексты, полученные из cURL под user-agent Google, и текст из вашего браузера со стандартным user-agent.
Сравниваем два HTML кода в любом онлайн-сервисе. Только будьте аккуратны, они сравнивают построчно. Любое изменение, даже точку, будут считать как добавленный/удаленный контент;
Используйте встроенную библиотеку python BeautifulSoup. Не будем вдаваться в подробности, так как эта тема отдельной статьи;
Различные расширения для браузеров, например SEO ALL STARS для Google Chrome. Единственный минус — многие расширения не умеют видеть текст под iframe. В любом случае, поэкспериментируйте.
Важное замечание: если на сайте стоит анти-бот система типа Cloudflare, то cURL такую защиту обойти никак не сможет. В этом случае используйте официальные инструменты от поисковиков (Google Search Console, Яндекс.Вебмастер) или обратитесь к владельцу сайта для предоставления доступа.
FAQ: Замена user-agent и проверка контента
Какой user-agent использовать для проверки сайта глазами Google?
Используйте актуальный user-agent Googlebot Smartphone, так как с 2019 года Google использует mobile-first индексацию даже для десктопных результатов. User-agent постоянно обновляется (evergreen версия Chrome), поэтому проверяйте актуальную версию в официальной документации Google.
Нужно ли проверять сайт глазами AI-краулеров (GPTBot, ClaudeBot)?
Да, особенно если ваш контент может быть использован для обучения AI-моделей. Трафик AI-краулеров вырос на 6900% с 2024 по 2026 год. Проверьте, что они видят на вашем сайте, и при необходимости настройте robots.txt для контроля доступа. Вы можете разрешить или запретить индексацию вашего контента AI-краулерами.
Прохождение базовой аутентификации: проверка закрытых страниц глазами поисковиков
Задача
Вы создали новый сайт или новую страницу, но она не доступна для пользователей и закрыта от посещений базовой авторизацией. Как протестировать такую страницу глазами Яндекса или Google? Это важно для проверки контента перед запуском сайта в продакшн.
Решение
cURL позволяет проходить базовую авторизацию на странице и получать любые данные, которые отдает сервер сайта.
Откройте терминал и введите туда curl -u "username:password" URL, и задайте user-agent ботов из инструкции выше: добавьте дополнительно -A "user-agent".
Что вводить:
Вместо username:password пропишите логин и пароль;
Вместо user-agent введите нужного поискового бота, например от Google:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
Параметр -u используется для указания учетных данных и говорит cURL, что страница с авторизацией.
Как это выглядит в терминале:

После того, как вы прошли базовую авторизацию и посмотрели страницу глазами Google, останется только сравнить полученный HTML от Google и в браузере и найти тот текст, который поисковик не видит. Для этого используйте инструкцию выше.
FAQ: Базовая аутентификация и закрытые страницы
Могут ли поисковые боты индексировать страницы под базовой авторизацией?
Нет, поисковые боты (Googlebot, Yandexbot) не могут пройти базовую HTTP-авторизацию, так как у них нет логина и пароля. Если страница закрыта авторизацией, она не будет проиндексирована. Используйте cURL для проверки контента таких страниц перед снятием защиты или для тестирования перед запуском.
Безопасно ли использовать cURL с логином и паролем в команде?
Команда cURL с логином и паролем видна в истории терминала. Для безопасности используйте переменные окружения или файлы конфигурации. В Windows: set USERNAME=login, затем curl -u "%USERNAME%:password" URL. В Linux/macOS: export USERNAME=login, затем используйте переменную в команде.
Проверка HTTP-заголовков и отслеживание цепочки редиректов: диагностика проблем с индексацией
Задача
Вы заходите на сайт и видите страницу с ответом сервера 200 OK. Пользователи жалуются, что по этой же странице у них открывается совсем другой контент или их перенаправляют в другое место. Вы хотите подтвердить жалобы пользователей и параллельно проверить ответы сервера и цепочки редиректов. Это критично для технического SEO-аудита, так как разные редиректы для ботов и пользователей могут привести к проблемам с индексацией.
Решение
Шаг 1: проверяем, что видит Google
Такая ситуация может возникнуть, когда продакт-менеджер проводил сплит-тест и нечаянно добавил в него поисковых ботов или нецелевую аудиторию. Возможен вариант, когда сплит-тест отключили, а разработчики неверно поправили техническую часть. Из-за этого контент, ответы сервера и HTTP-заголовки могут выдаваться разные.
Вначале проверяем, нет ли лишних редиректов для бота Google и какие HTTP-заголовки ему возвращаются:
curl -sSL -D - -A "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" http://pr-cy.ru
Немного позже расшифруем все параметры в этом запросе.
Получаем следующий ответ, где видим HTTP-заголовки и цепочки редиректов:
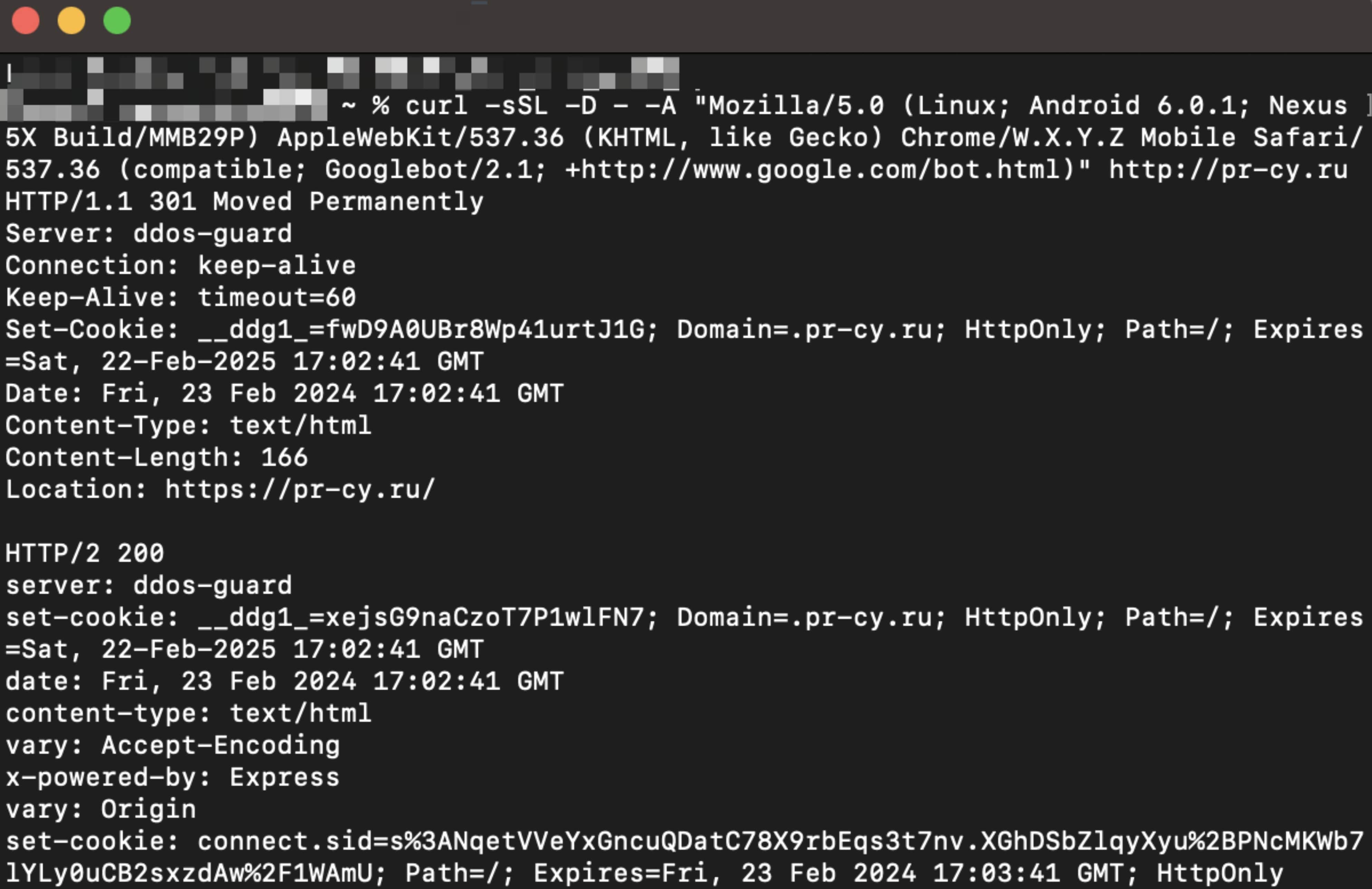
Видим, что для бота срабатывает один 301 редирект. Но это не из-за проблемы с сервером, а грамотно настроенные редиректы с HTTP на HTTPS. Запоминаем результат.
Шаг 2: проверяем, нет ли редиректов у пользователей, которые столкнулись с проблемами
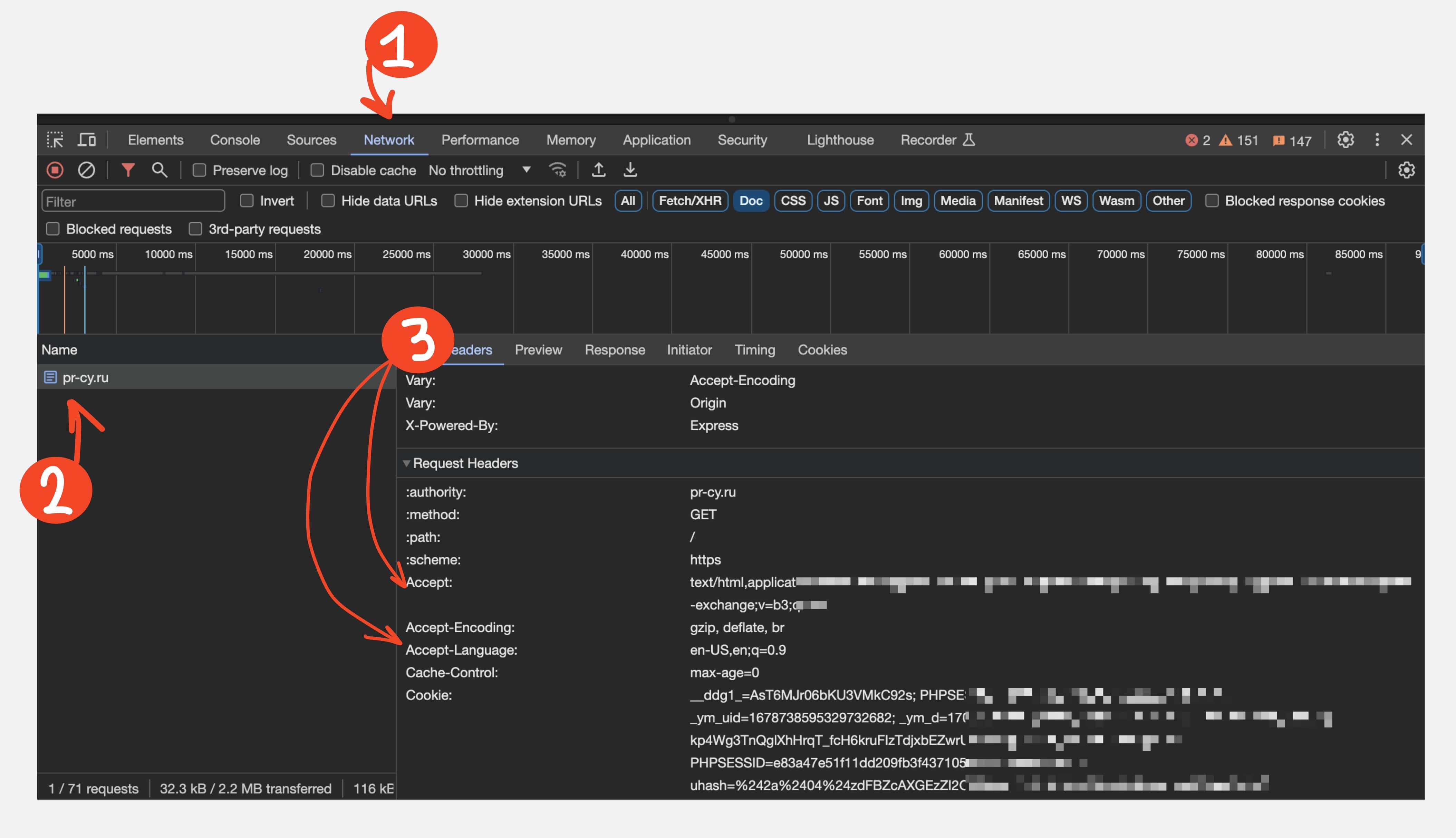
Для этого нужно знать user-agent, accept и accept-language пользователя, у которого имеется проблема. Про accept и accept-language подробнее можно почитать в документации Mozilla.
Данные об accept-ах и user-agent узнаем через онлайн-сервис webtools или через браузер пользователя: DevTools -> Network -> Headers -> Request Headers.
После того как узнали эти данные, вводим в консоль следующий запрос:
curl -sSL -D - -H "User-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/105.0" -H "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8" -H "Accept-Language: en-US,en;q=0.5" http://pr-cy.ru
Получаем ответ, где видим HTTP-заголовки и цепочки редиректов, только уже для пользователя с проблемой. Теперь нужно сравнить ответы сервера для пользователей и ответы сервера для Google.
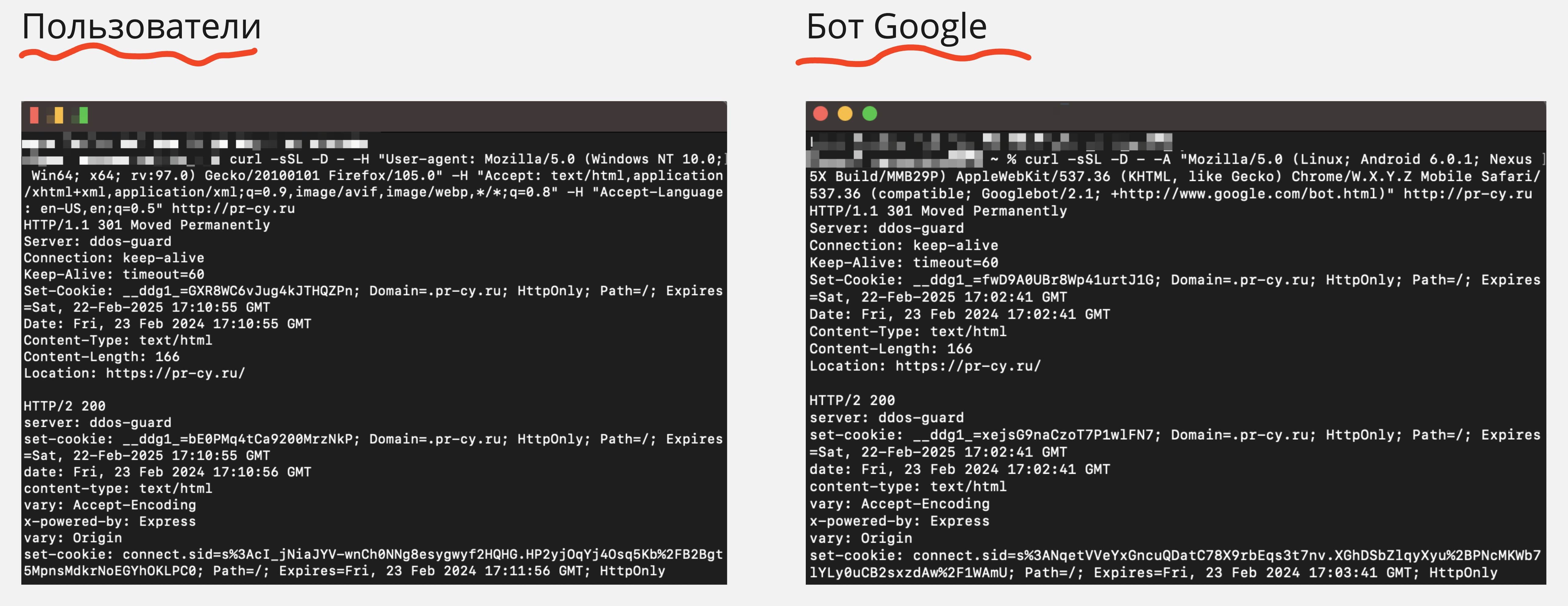
На скрине мы видим, что c HTTP-заголовками все в порядке и цепочки редиректов для пользователей и ботов одинаковые.
Рекомендация: на всякий случай проверьте тоже самое, только со своим user-agent. И сравните, что видят пользователи, что Google, а что вы.
Параметры в запросе:
-s — этот флаг означает “тихий” режим и не выводит информацию в терминал о ходе процесса;
-S — этот флаг не выводит ошибки возникающие в процессе запроса, чтобы не засорять терминал;
-L — этот флаг позволяет cURL следовать редиректам в запросе и показывать всю цепочку;
-D - — этот флаг выводим заголовки HTTP headers в ответ терминала, и не записывает в файл;
-H - — этот флаг указывает на добавление заголовка к HTTP-запросу. Он позволяет уникализировать запрос и притвориться любым пользователем.
FAQ: HTTP-заголовки и редиректы
Почему важно проверять редиректы через cURL, а не через браузер?
Браузер может кэшировать редиректы или показывать только финальный результат. cURL показывает всю цепочку редиректов (301, 302, 307 и т.д.) и HTTP-заголовки на каждом этапе. Это критично для SEO, так как длинные цепочки редиректов (более 3-5) могут замедлять индексацию или приводить к потере "веса" страницы.
Что делать, если для Googlebot и пользователей разные редиректы?
Это серьезная проблема для SEO. Поисковики могут воспринять это как попытку обмана (cloaking). Убедитесь, что все пользователи (включая ботов) получают одинаковые редиректы и контент. Проверьте настройки A/B-тестов, геотаргетинга и сплит-тестирования — они не должны влиять на поисковых ботов.
Резюмируем: когда использовать cURL для технического SEO-аудита
cURL — простая программа, которая имеется по умолчанию практически на всех компьютерах Windows 10+, macOS и Linux. Она позволяет делать HTTP-запросы к любому сайту и получить HTTP-заголовки и тело страницы. В 2026 году cURL остается одним из самых надежных инструментов для технического SEO-аудита, особенно когда нужно точно понять, что видит поисковый бот.
Мы разобрали три основных ситуации, в которых SEO-специалист может использовать cURL:
Просмотреть страницы глазами поисковика — независимо от того, работают ли официальные сервисы от Яндекса и Google. Особенно актуально для проверки контента, доступного AI-краулерам (GPTBot, ClaudeBot, PerplexityBot), которые активно индексируют контент с 2024 года;
Получить тело страницы под авторизацией — когда страница находится под базовой авторизацией и нужно проверить, что видят поисковые боты;
Отследить редиректы и HTTP-заголовки — проверить, действительно ли вам, вашим пользователям и поисковым ботам отдаются одинаковые редиректы и HTTP-заголовки. Это критично для избежания проблем с индексацией.
FAQ: Использование cURL для SEO
Можно ли использовать cURL вместо Google Search Console для проверки индексации?
cURL и Google Search Console решают разные задачи. Search Console показывает статистику индексации, позиции и ошибки краулинга. cURL позволяет увидеть "сырой" HTML-код, который получает бот при запросе страницы. Используйте их вместе: Search Console для общей картины, cURL для детальной диагностики конкретных страниц.
Как часто нужно проверять сайт через cURL?
Регулярные проверки через cURL нужны при техническом аудите сайта, после изменений в структуре или контенте, при подозрении на проблемы с индексацией. Для постоянного мониторинга лучше использовать автоматизированные инструменты, например, анализ сайта PR-CY, который отслеживает технические параметры сайта 24/7.
Что делать, если cURL показывает другой контент, чем видит пользователь в браузере?
Это серьезная проблема для SEO. Если поисковый бот видит другой контент, чем пользователь, это может привести к проблемам с индексацией. Проверьте: нет ли клиентского рендеринга JavaScript (боты могут не выполнять JS), нет ли геотаргетинга или A/B-тестов, которые влияют на контент. Убедитесь, что основной контент доступен в исходном HTML без JavaScript.







