
Содержание
Краткое саммари
Метатеги robots и заголовок X-Robots-Tag помогают точечно управлять индексацией страниц и файлов в Яндексе и Google. Мы разобрали, какие директивы реально работают, как избежать конфликтов с robots.txt, как учитывать mobile-first индексацию и какие правовые риски есть у страниц с персональными данными.
Кому стоит прочитать статью:
- SEO-специалистам, которые управляют индексом больших сайтов и интернет-магазинов.
- Вебмастерам и разработчикам, которые настраивают robots.txt, метатеги и серверные заголовки.
- Редакторам и владельцам проектов, которым важно не выводить в поиск служебные страницы.
Метатеги robots и X-Robots-Tag нужны, чтобы указать поисковому роботу, как индексировать страницу или файл. С их помощью можно открывать и закрывать URL для индексации, а также разрешать или запрещать переход по ссылкам. Для SEO это базовый инструмент, который напрямую влияет на видимость сайта в поиске.
Поисковой робот или краулер сканирует сайт, переходит по доступным ссылкам, анализирует контент и передает данные в индекс поисковой системы. Если URL не просканирован, попасть на него можно только по прямой ссылке или из внешних источников. Базовые правила обхода задаются в robots.txt, а точечные настройки удобнее делать через robots и X-Robots-Tag.
Метатег robots и файл robots.txt для SEO индексации — в чем разница
Файл robots.txt лежит в корне сайта, и краулер начинает обход именно с него. Через него задают правила обхода разделов и шаблонов URL. Этот файл регулирует доступ к сканированию, но не является гарантированным инструментом удаления страниц из индекса.
Статья по теме: Как составить robots.txt самостоятельно
Метатег robots размещают в HTML страницы, обычно внутри блока head. Он отвечает за то, как страница должна вести себя в индексе и в выдаче. Если нужно закрыть конкретную страницу от показа в поиске, обычно применяют noindex в метатеге или в X-Robots-Tag.
X-Robots-Tag работает на уровне HTTP-заголовка. Его используют для управления индексацией не только HTML, но и PDF, изображений, видео и других типов файлов, где метатег robots вставить нельзя.
Ограничения и требования законодательства РФ
Если страница содержит персональные данные, оператор обязан соблюдать требования 152-ФЗ и 149-ФЗ: определить правовое основание обработки, ограничить публикацию избыточных данных и обеспечить защиту информации.
Для служебных страниц, личных кабинетов, CRM-выгрузок, страниц с заявками и иными персональными данными важно заранее закрывать индексацию через robots или X-Robots-Tag, а не рассчитывать только на robots.txt.
FAQ по разделу
Можно ли удалить страницу из поиска только через robots.txt?
robots.txt ограничивает обход, но не дает надежного удаления из индекса. Для удаления обычно используют noindex и корректный ответ сервера.
Когда лучше выбрать X-Robots-Tag вместо метатега?
Если вам нужно управлять индексацией PDF, изображений и других не-HTML файлов.
Метатеги краулеров и директивы индексации страниц
Принцип работы краулеров похож у всех поисковых систем, но поддержка директив отличается. Для SEO в Яндексе и Google обычно используют два механизма:
robots — правила для конкретной HTML-страницы в head;
X-Robots-Tag — правила в HTTP-заголовке конкретного URL или группы файлов.
В директивах задается поведение робота: индексировать страницу, обходить ссылки, показывать фрагменты контента или скрывать их. Базовый набор директив пересекается, но часть инструкций доступна только в отдельных поисковых системах.
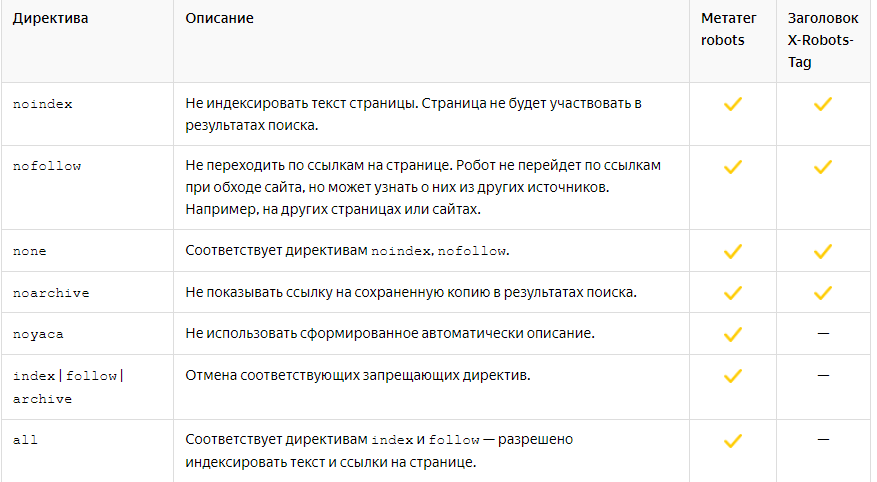
Для Google дополнительно важны директивы управления видом сниппета и медиа в выдаче: indexifembedded, max-snippet, max-image-preview, max-video-preview, noimageindex, notranslate, unavailable_after. Директива nositelinkssearchbox устарела для современных сценариев и больше не относится к приоритетным инструментам оптимизации сниппета.
Для пользователей из России при работе с документацией лучше использовать официальные источники, которые стабильно открываются: раздел Яндекс Вебмастера по метатегам и официальную справку Google Search Central.
FAQ по разделу
Какие директивы чаще всего применяют в ежедневной работе?
noindex, nofollow, max-snippet и max-image-preview.
Есть ли единый набор директив для всех поисковиков?
Нет, пересечение есть, но часть директив действует только в конкретной системе.
Нужно ли дублировать директивы в robots и X-Robots-Tag?
Только если вы тщательно контролируете оба уровня и проверяете итоговый HTTP-ответ.
Метатег robots: настройка noindex, nofollow и сниппетов
В Яндексе и Google структура метатега robots совпадает. В атрибуте content указывают одну или несколько директив через запятую.
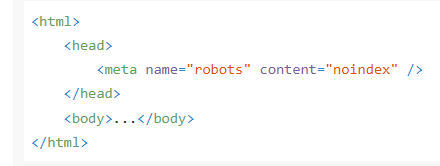
По умолчанию страница доступна для индексации и обхода, поэтому отдельная директива all обычно не нужна. Для рабочих задач чаще используют запрещающие директивы и их комбинации.

Если нужно закрыть страницу только для робота Яндекса, задают целевой name:
<meta name="yandex" content="noindex" />
Примеры сочетаний директив:
content="noindex,follow" — страница не участвует в поиске, но робот может переходить по ссылкам;
content="noindex,nofollow" — страница закрыта от индексации, переход по ссылкам ограничен;
content="index,follow" — стандартная индексация страницы и ссылок.
Google также позволяет задавать директивы для отдельных роботов, например для AdsBot-Google:
<meta name="AdsBot-Google" content="noindex">
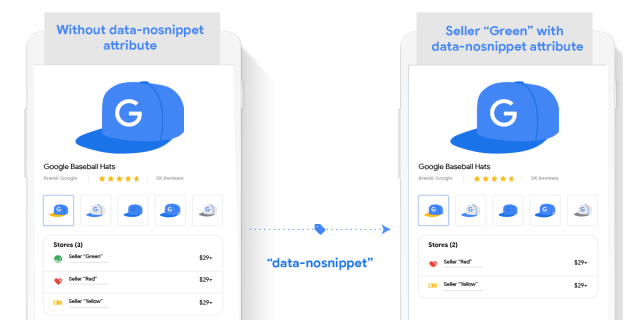
Для управления фрагментами текста в сниппете применяют атрибут data-nosnippet.
Так можно исключить отдельные фрагменты из показа в выдаче и сохранить остальной текст доступным для отображения. Пример:
<p>Пример текста из сниппета, который можно показывать <span data-nosnippet>но эту часть показывать не нужно</span></p> <div data-nosnippet>и этот блок тоже скрываем</div> <div data-nosnippet="true">и этот тоже</div>
Правильный синтаксис HTML и аккуратная работа с директивами важны для стабильной индексации. Ошибка в метатеге может закрыть релевантную страницу от поиска или, наоборот, оставить в индексе служебный URL. Для больших проектов, где много карточек, фильтров и технических страниц, robots помогает поддерживать индекс в рабочем состоянии.
Метатег robots также используют в разработке и при запуске новых разделов, чтобы временно закрыть тестовые страницы, дубли и служебные шаблоны до релиза.
FAQ по разделу
Что выбрать для карточек товаров в листингах?
Чаще используют index,follow для важных URL и noindex для техничных дублей.
Можно ли ставить noindex на странице, закрытой через disallow?
Это рискованно, потому что робот может не прочитать noindex из-за запрета на обход.
Когда использовать data-nosnippet?
Если вам нужно скрыть от выдачи часть текста, например, служебные блоки или внутренние пометки.
X-Robots-Tag: управление индексацией PDF, изображений и других файлов
Для X-Robots-Tag действует та же логика директив, что и для robots, но применяется она на уровне HTTP-ответа. Это основной способ задать noindex для файлов, где нет HTML-head.
X-Robots-Tag добавляют через серверную конфигурацию Apache, Nginx или через CDN-правила. Перед публикацией важно проверить staging и бэкапы, потому что ошибка в серверных правилах может затронуть целые разделы сайта.
Пример для PDF в Apache:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
Пример ответа сервера с директивами:
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT X-Robots-Tag: noindex, nofollow X-Robots-Tag: noarchive
X-Robots-Tag полезен, когда нужно массово закрыть медиафайлы, технические PDF или временные документы. Если URL одновременно закрыт в robots.txt через disallow, робот может не дойти до страницы и не увидеть директиву noindex. Поэтому для удаления из индекса сначала обеспечивают доступ к обходу, затем задают noindex, и только после деиндексации при необходимости ограничивают сканирование.
Для крупных e-commerce проектов это особенно важно в сезоны распродаж. Страницы акций, тестовые лендинги и временные коллекции безопаснее держать под управлением noindex или X-Robots-Tag, чтобы не получить преждевременную индексацию до запуска кампании.
Настройка метатегов не является отдельным фактором ранжирования, но это критичный технический слой SEO. Он влияет на состав индекса, чистоту выдачи и расход краулингового бюджета.
FAQ по разделу
Когда X-Robots-Tag подходит лучше, чем robots?
Если речь идет о PDF, изображениях, видео и других не-HTML файлах.
Можно ли задавать X-Robots-Tag выборочно?
Да, через шаблоны URL, расширения файлов и условия в конфигурации сервера.
Как быстро проверить результат?
Посмотреть HTTP-ответ страницы или файла и убедиться, что заголовок отдается корректно.
Последние обновления по robots и X-Robots-Tag
- Google завершил переход на mobile-first индексацию. В 2024 году Google завершил rollout mobile-first индексации. Метатеги и контент мобильной версии должны полностью совпадать с основной версией, иначе страница может терять видимость.
- Документация Google Search Central получила уточнения по обработке robots-правил. В 2025-2026 годах в документации обновляли пояснения по page-level управлению и поведению robots-метатегов. Логика директив в целом стабильна, но акцент смещается в сторону точной технической реализации и проверки HTTP-ответов.
- Яндекс сохраняет базовую модель директив robots и X-Robots-Tag. Для Яндекса по-прежнему рабочими остаются noindex и nofollow, а для удаления URL из поиска важнее корректный noindex, чем попытка решить задачу только через robots.txt.
Система robots и X-Robots-Tag остается одним из самых надежных инструментов технического SEO. Чем точнее вы разделяете задачи обхода, индексации и управления сниппетом, тем стабильнее контролируете присутствие страниц и файлов в поисковой выдаче.
FAQ по разделу
Нужно ли пересматривать старые настройки robots?
Да, особенно после редизайна, миграции или запуска мобильной версии.
Какой минимальный аудит делать регулярно?
Нужно проверять robots.txt, метатеги robots, X-Robots-Tag и индексацию ключевых URL в Яндекс Вебмастере и Google Search Console.






